 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-distribution Reject Option Method for Dataset Shift Problem in Early Disease Onset Prediction
May 30, 2024Machine learning is increasingly used to predict lifestyle-related disease onset using health and medical data. However, the prediction effectiveness is hindered by dataset shift, which involves discrepancies in data distribution between the training and testing datasets, misclassifying out-of-distribution (OOD) data. To diminish dataset shift effects, this paper proposes the out-of-distribution reject option for prediction (ODROP), which integrates OOD detection models to preclude OOD data from the prediction phase. We investigated the efficacy of five OOD detection methods (variational autoencoder, neural network ensemble std, neural network ensemble epistemic, neural network energy, and neural network gaussian mixture based energy measurement) across two datasets, the Hirosaki and Wakayama health checkup data, in the context of three disease onset prediction tasks: diabetes, dyslipidemia, and hypertension. To evaluate the ODROP method, we trained disease onset prediction models and OOD detection models on Hirosaki data and used AUROC-rejection curve plots from Wakayama data. The variational autoencoder method showed superior stability and magnitude of improvement in Area Under the Receiver Operating Curve (AUROC) in five cases: AUROC in the Wakayama data was improved from 0.80 to 0.90 at a 31.1% rejection rate for diabetes onset and from 0.70 to 0.76 at a 34% rejection rate for dyslipidemia. We categorized dataset shifts into two types using SHAP clustering - those that considerably affect predictions and those that do not. We expect that this classification will help standardize measuring instruments. This study is the first to apply OOD detection to actual health and medical data, demonstrating its potential to substantially improve the accuracy and reliability of disease prediction models amidst dataset shift.
Individual health-disease phase diagrams for disease prevention based on machine learning
May 31, 2022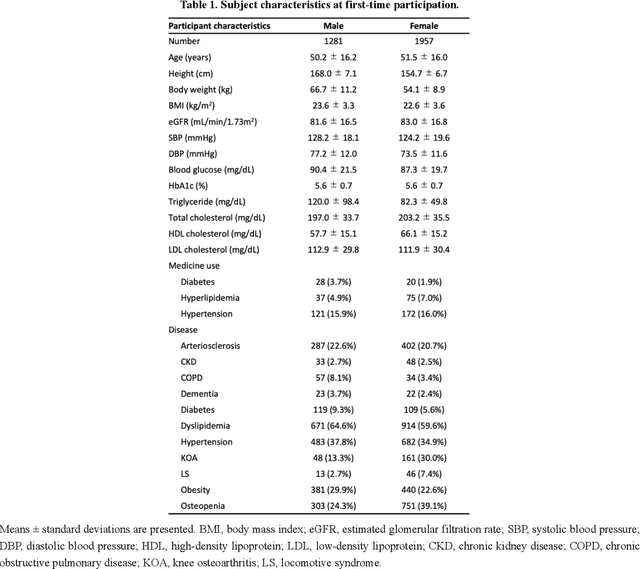
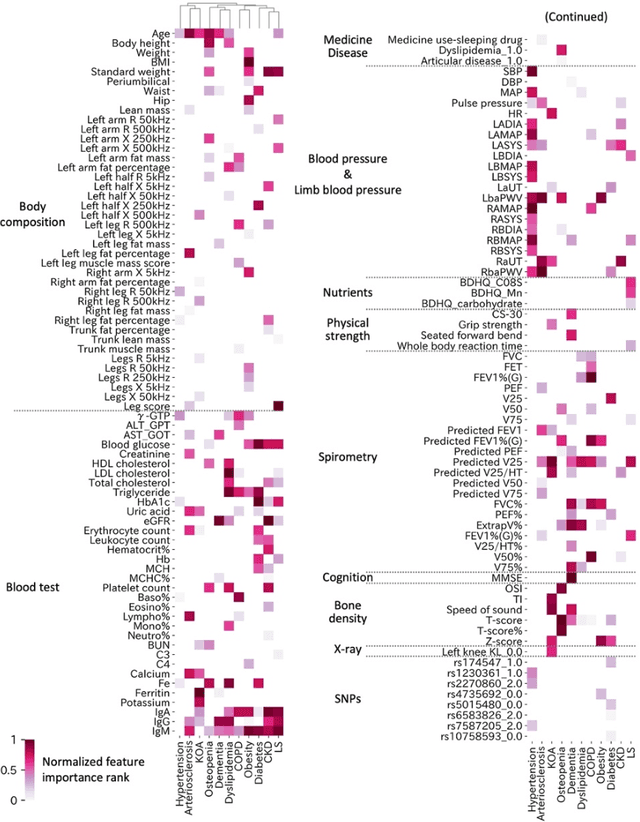

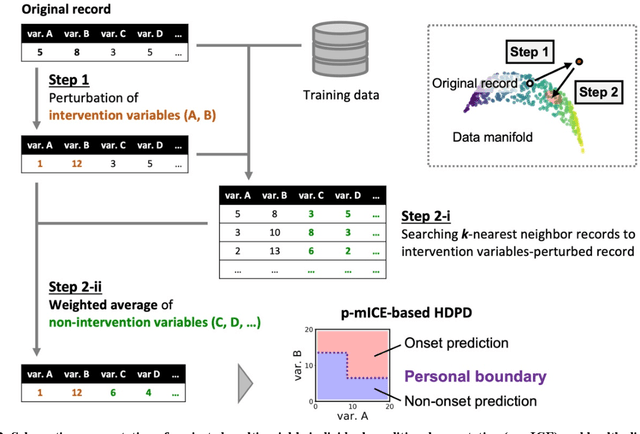
Early disease detection and prevention methods based on effective interventions are gaining attention. Machine learning technology has enabled precise disease prediction by capturing individual differences in multivariate data. Progress in precision medicine has revealed that substantial heterogeneity exists in health data at the individual level and that complex health factors are involved in the development of chronic diseases. However, it remains a challenge to identify individual physiological state changes in cross-disease onset processes because of the complex relationships among multiple biomarkers. Here, we present the health-disease phase diagram (HDPD), which represents a personal health state by visualizing the boundary values of multiple biomarkers that fluctuate early in the disease progression process. In HDPDs, future onset predictions are represented by perturbing multiple biomarker values while accounting for dependencies among variables. We constructed HDPDs for 11 non-communicable diseases (NCDs) from a longitudinal health checkup cohort of 3,238 individuals, comprising 3,215 measurement items and genetic data. Improvement of biomarker values to the non-onset region in HDPD significantly prevented future disease onset in 7 out of 11 NCDs. Our results demonstrate that HDPDs can represent individual physiological states in the onset process and be used as intervention goals for disease prevention.