 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-distribution Reject Option Method for Dataset Shift Problem in Early Disease Onset Prediction
May 30, 2024Machine learning is increasingly used to predict lifestyle-related disease onset using health and medical data. However, the prediction effectiveness is hindered by dataset shift, which involves discrepancies in data distribution between the training and testing datasets, misclassifying out-of-distribution (OOD) data. To diminish dataset shift effects, this paper proposes the out-of-distribution reject option for prediction (ODROP), which integrates OOD detection models to preclude OOD data from the prediction phase. We investigated the efficacy of five OOD detection methods (variational autoencoder, neural network ensemble std, neural network ensemble epistemic, neural network energy, and neural network gaussian mixture based energy measurement) across two datasets, the Hirosaki and Wakayama health checkup data, in the context of three disease onset prediction tasks: diabetes, dyslipidemia, and hypertension. To evaluate the ODROP method, we trained disease onset prediction models and OOD detection models on Hirosaki data and used AUROC-rejection curve plots from Wakayama data. The variational autoencoder method showed superior stability and magnitude of improvement in Area Under the Receiver Operating Curve (AUROC) in five cases: AUROC in the Wakayama data was improved from 0.80 to 0.90 at a 31.1% rejection rate for diabetes onset and from 0.70 to 0.76 at a 34% rejection rate for dyslipidemia. We categorized dataset shifts into two types using SHAP clustering - those that considerably affect predictions and those that do not. We expect that this classification will help standardize measuring instruments. This study is the first to apply OOD detection to actual health and medical data, demonstrating its potential to substantially improve the accuracy and reliability of disease prediction models amidst dataset shift.
Health improvement framework for planning actionable treatment process using surrogate Bayesian model
Nov 13, 2020

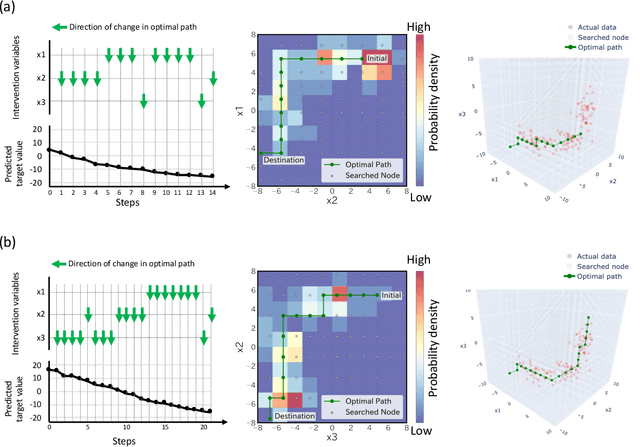
Clinical decision making regarding treatments based on personal characteristics leads to effective health improvements. Machine learning (ML) has been the primary concern of diagnosis support according to comprehensive patient information. However, the remaining prominent issue is the development of objective treatment processes in clinical situations. This study proposes a novel framework to plan treatment processes in a data-driven manner. A key point of the framework is the evaluation of the "actionability" for personal health improvements by using a surrogate Bayesian model in addition to a high-performance nonlinear ML model. We first evaluated the framework from the viewpoint of its methodology using a synthetic dataset. Subsequently, the framework was applied to an actual health checkup dataset comprising data from 3,132 participants, to improve systolic blood pressure values at the individual level. We confirmed that the computed treatment processes are actionable and consistent with clinical knowledge for lowering blood pressure. These results demonstrate that our framework could contribute toward decision making in the medical field, providing clinicians with deeper insights.