 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Velocity: A Variance Perspective on Flow Matching
Feb 05, 2026While flow matching is elegant, its reliance on single-sample conditional velocities leads to high-variance training targets that destabilize optimization and slow convergence. By explicitly characterizing this variance, we identify 1) a high-variance regime near the prior, where optimization is challenging, and 2) a low-variance regime near the data distribution, where conditional and marginal velocities nearly coincide. Leveraging this insight, we propose Stable Velocity, a unified framework that improves both training and sampling. For training, we introduce Stable Velocity Matching (StableVM), an unbiased variance-reduction objective, along with Variance-Aware Representation Alignment (VA-REPA), which adaptively strengthen auxiliary supervision in the low-variance regime. For inference, we show that dynamics in the low-variance regime admit closed-form simplifications, enabling Stable Velocity Sampling (StableVS), a finetuning-free acceleration. Extensive experiments on ImageNet $256\times256$ and large pretrained text-to-image and text-to-video models, including SD3.5, Flux, Qwen-Image, and Wan2.2, demonstrate consistent improvements in training efficiency and more than $2\times$ faster sampling within the low-variance regime without degrading sample quality. Our code is available at https://github.com/linYDTHU/StableVelocity.
SymmetricDiffusers: Learning Discrete Diffusion on Finite Symmetric Groups
Oct 03, 2024
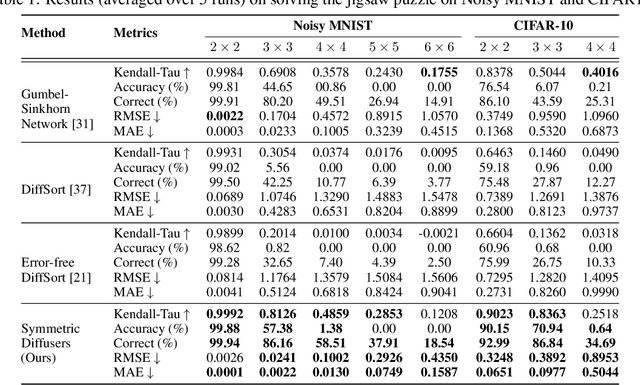
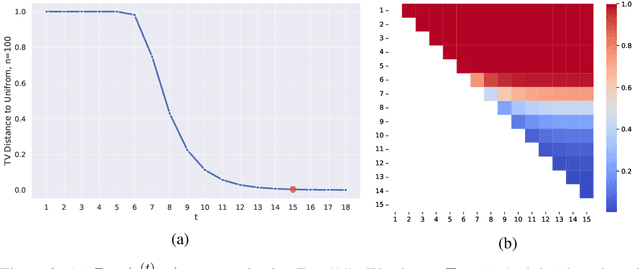

Finite symmetric groups $S_n$ are essential in fields such as combinatorics, physics, and chemistry. However, learning a probability distribution over $S_n$ poses significant challenges due to its intractable size and discrete nature. In this paper, we introduce SymmetricDiffusers, a novel discrete diffusion model that simplifies the task of learning a complicated distribution over $S_n$ by decomposing it into learning simpler transitions of the reverse diffusion using deep neural networks. We identify the riffle shuffle as an effective forward transition and provide empirical guidelines for selecting the diffusion length based on the theory of random walks on finite groups. Additionally, we propose a generalized Plackett-Luce (PL) distribution for the reverse transition, which is provably more expressive than the PL distribution. We further introduce a theoretically grounded "denoising schedule" to improve sampling and learning efficiency. Extensive experiments show that our model achieves state-of-the-art or comparable performances on solving tasks including sorting 4-digit MNIST images, jigsaw puzzles, and traveling salesman problems. Our code is released at https://github.com/NickZhang53/SymmetricDiffusers.