 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
Dec 12, 2018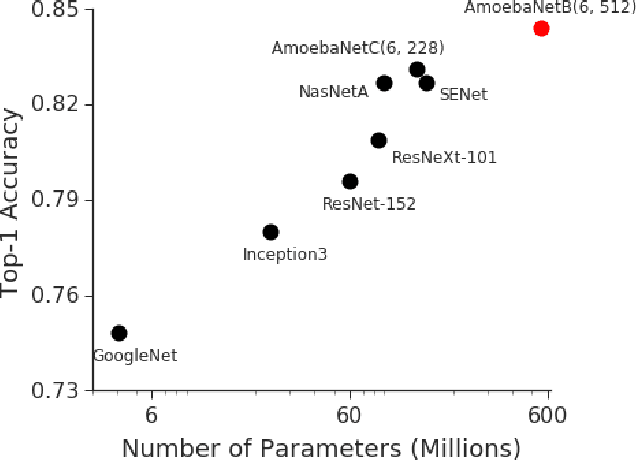

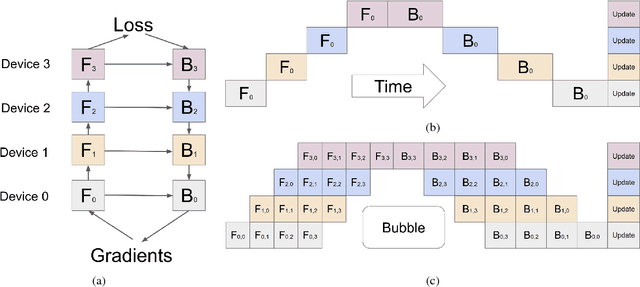
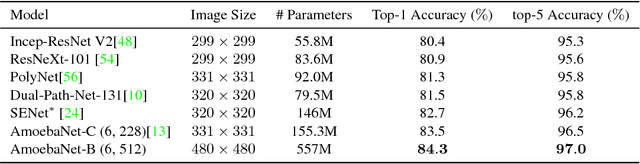
GPipe is a scalable pipeline parallelism library that enables learning of giant deep neural networks. It partitions network layers across accelerators and pipelines execution to achieve high hardware utilization. It leverages recomputation to minimize activation memory usage. For example, using partitions over 8 accelerators, it is able to train networks that are 25x larger, demonstrating its scalability. It also guarantees that the computed gradients remain consistent regardless of the number of partitions. It achieves an almost linear speed up without any changes in the model parameters: when using 4x more accelerators, training the same model is up to 3.5x faster. We train a 557 million parameters AmoebaNet model on ImageNet and achieve a new state-of-the-art 84.3% top-1 / 97.0% top-5 accuracy on ImageNet 2012 dataset. Finally, we use this learned model to finetune multiple popular image classification datasets and obtain competitive results, including pushing the CIFAR-10 accuracy to 99% and CIFAR-100 accuracy to 91.3%.