 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Taxonomy and Analysis of Talking Head Synthesis: Techniques for Portrait Generation, Driving Mechanisms, and Editing
Jun 18, 2024



Talking head synthesis, an advanced method for generating portrait videos from a still image driven by specific content, has garnered widespread attention in virtual reality, augmented reality and game production. Recently, significant breakthroughs have been made with the introduction of novel models such as the transformer and the diffusion model. Current methods can not only generate new content but also edit the generated material. This survey systematically reviews the technology, categorizing it into three pivotal domains: portrait generation, driven mechanisms, and editing techniques. We summarize milestone studies and critically analyze their innovations and shortcomings within each domain. Additionally, we organize an extensive collection of datasets and provide a thorough performance analysis of current methodologies based on various evaluation metrics, aiming to furnish a clear framework and robust data support for future research. Finally, we explore application scenarios of talking head synthesis, illustrate them with specific cases, and examine potential future directions.
A Lightweight Recurrent Grouping Attention Network for Video Super-Resolution
Sep 25, 2023
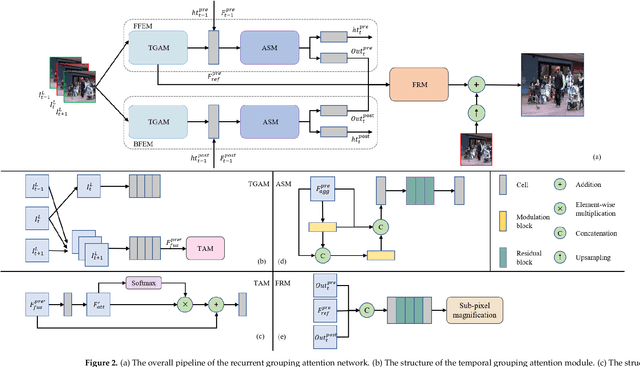
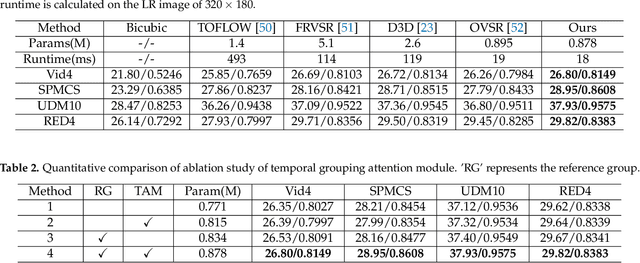

Effective aggregation of temporal information of consecutive frames is the core of achieving video super-resolution. Many scholars have utilized structures such as sliding windows and recurrent to gather spatio-temporal information of frames. However, although the performance of the constructed VSR models is improving, the size of the models is also increasing, exacerbating the demand on the equipment. Thus, to reduce the stress on the device, we propose a novel lightweight recurrent grouping attention network. The parameters of this model are only 0.878M, which is much lower than the current mainstream model for studying video super-resolution. We design forward feature extraction module and backward feature extraction module to collect temporal information between consecutive frames from two directions. Moreover, a new grouping mechanism is proposed to efficiently collect spatio-temporal information of the reference frame and its neighboring frames. The attention supplementation module is presented to further enhance the information gathering range of the model. The feature reconstruction module aims to aggregate information from different directions to reconstruct high-resolution features. Experiments demonstrate that our model achieves state-of-the-art performance on multiple datasets.
Considering Image Information and Self-similarity: A Compositional Denoising Network
Sep 14, 2022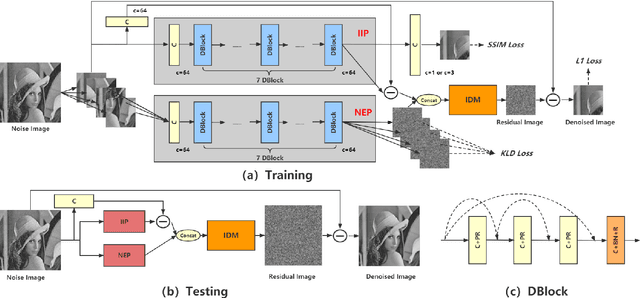
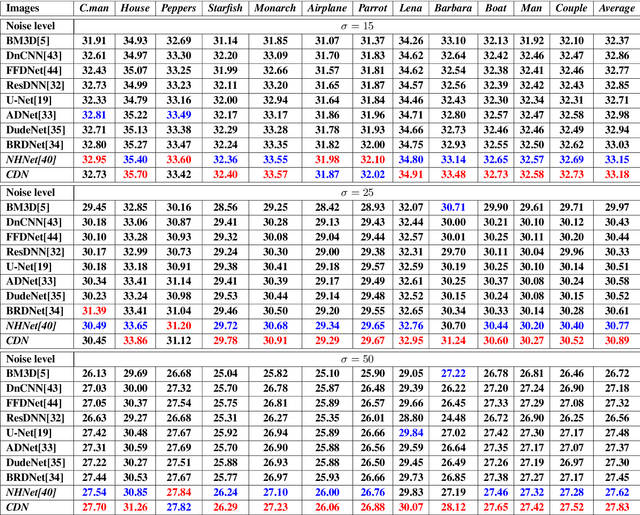
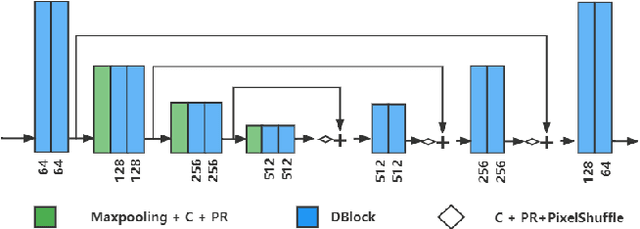

Recently, convolutional neural networks (CNNs) have been widely used in image denoising. Existing methods benefited from residual learning and achieved high performance. Much research has been paid attention to optimizing the network architecture of CNN but ignored the limitations of residual learning. This paper suggests two limitations of it. One is that residual learning focuses on estimating noise, thus overlooking the image information. The other is that the image self-similarity is not effectively considered. This paper proposes a compositional denoising network (CDN), whose image information path (IIP) and noise estimation path (NEP) will solve the two problems, respectively. IIP is trained by an image-to-image way to extract image information. For NEP, it utilizes the image self-similarity from the perspective of training. This similarity-based training method constrains NEP to output a similar estimated noise distribution for different image patches with a specific kind of noise. Finally, image information and noise distribution information will be comprehensively considered for image denoising. Experiments show that CDN achieves state-of-the-art results in synthetic and real-world image denoising. Our code will be released on https://github.com/JiaHongZ/CDN.
A Novel Dual Dense Connection Network for Video Super-resolution
Mar 05, 2022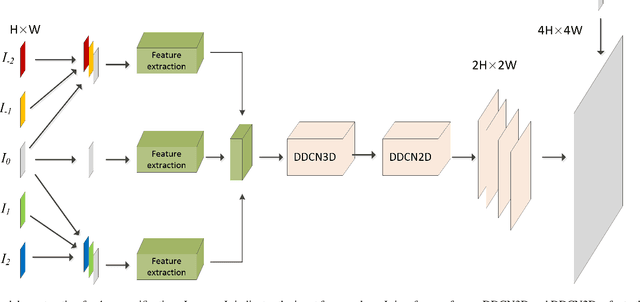
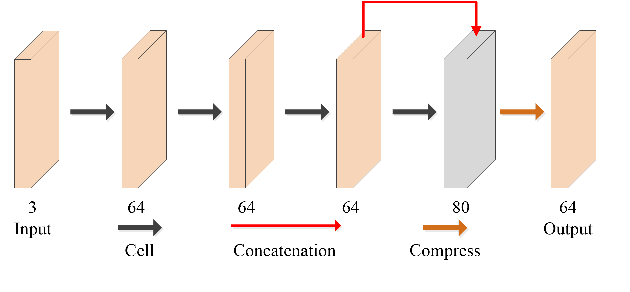
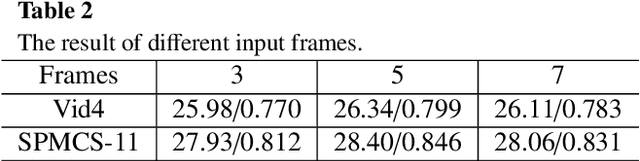
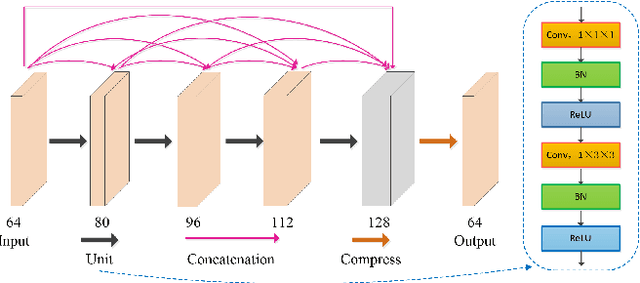
Video super-resolution (VSR) refers to the reconstruction of high-resolution (HR) video from the corresponding low-resolution (LR) video. Recently, VSR has received increasing attention. In this paper, we propose a novel dual dense connection network that can generate high-quality super-resolution (SR) results. The input frames are creatively divided into reference frame, pre-temporal group and post-temporal group, representing information in different time periods. This grouping method provides accurate information of different time periods without causing time information disorder. Meanwhile, we produce a new loss function, which is beneficial to enhance the convergence ability of the model. Experiments show that our model is superior to other advanced models in Vid4 datasets and SPMCS-11 datasets.