 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Recurrent Grouping Attention Network for Video Super-Resolution
Sep 25, 2023
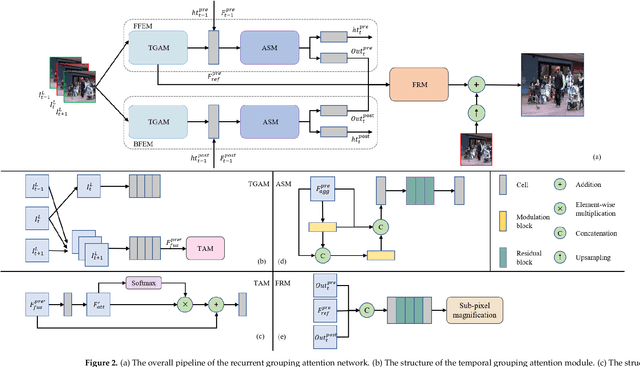
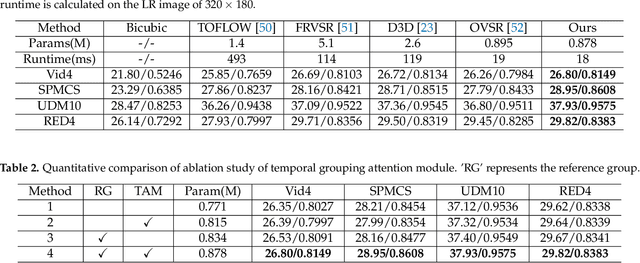

Effective aggregation of temporal information of consecutive frames is the core of achieving video super-resolution. Many scholars have utilized structures such as sliding windows and recurrent to gather spatio-temporal information of frames. However, although the performance of the constructed VSR models is improving, the size of the models is also increasing, exacerbating the demand on the equipment. Thus, to reduce the stress on the device, we propose a novel lightweight recurrent grouping attention network. The parameters of this model are only 0.878M, which is much lower than the current mainstream model for studying video super-resolution. We design forward feature extraction module and backward feature extraction module to collect temporal information between consecutive frames from two directions. Moreover, a new grouping mechanism is proposed to efficiently collect spatio-temporal information of the reference frame and its neighboring frames. The attention supplementation module is presented to further enhance the information gathering range of the model. The feature reconstruction module aims to aggregate information from different directions to reconstruct high-resolution features. Experiments demonstrate that our model achieves state-of-the-art performance on multiple datasets.
A Novel Dual Dense Connection Network for Video Super-resolution
Mar 05, 2022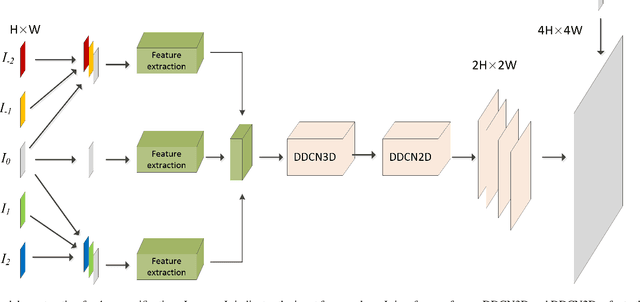
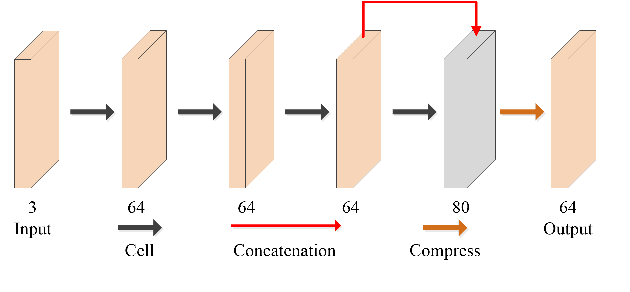
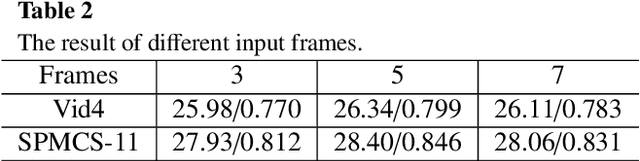
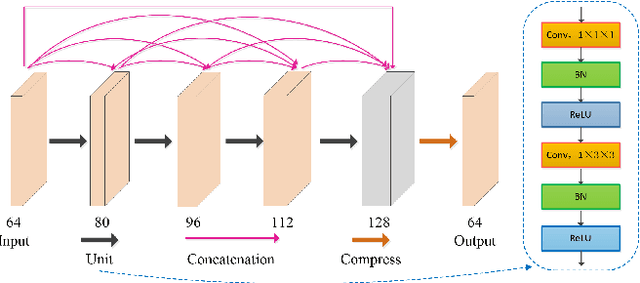
Video super-resolution (VSR) refers to the reconstruction of high-resolution (HR) video from the corresponding low-resolution (LR) video. Recently, VSR has received increasing attention. In this paper, we propose a novel dual dense connection network that can generate high-quality super-resolution (SR) results. The input frames are creatively divided into reference frame, pre-temporal group and post-temporal group, representing information in different time periods. This grouping method provides accurate information of different time periods without causing time information disorder. Meanwhile, we produce a new loss function, which is beneficial to enhance the convergence ability of the model. Experiments show that our model is superior to other advanced models in Vid4 datasets and SPMCS-11 datasets.