 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrainable Adaptive Window Switching for Speech Enhancement
Nov 05, 2018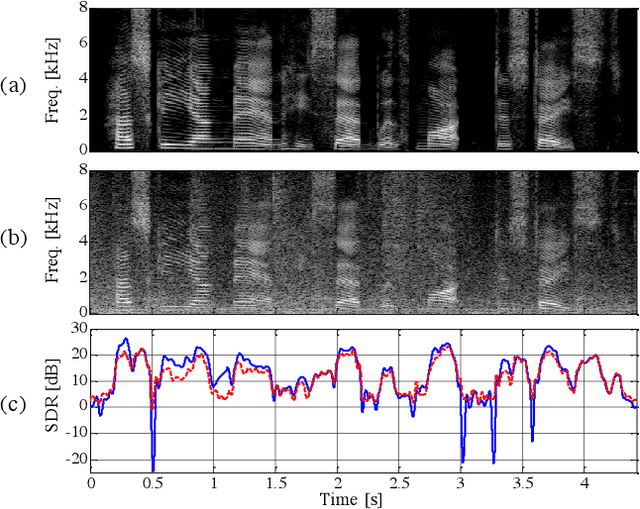

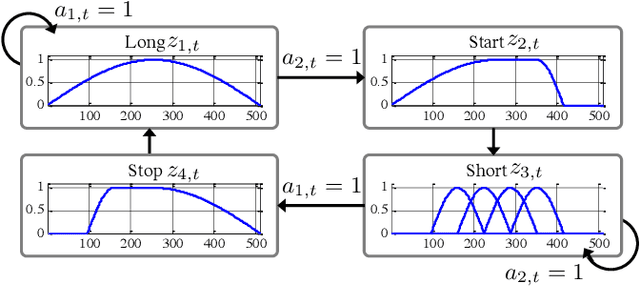
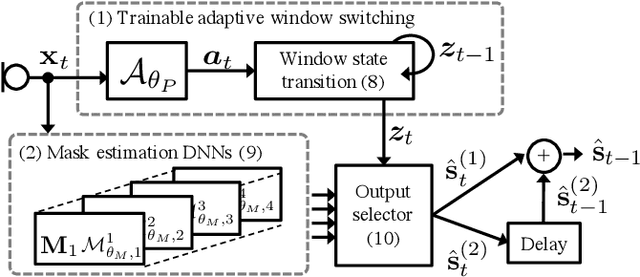
This study proposes a trainable adaptive window switching (AWS) method and apply it to a deep-neural-network (DNN) for speech enhancement in the modified discrete cosine transform domain. Time-frequency (T-F) mask processing in the short-time Fourier transform (STFT)-domain is a typical speech enhancement method. To recover the target signal precisely, DNN-based short-time frequency transforms have recently been investigated and used instead of the STFT. However, since such a fixed-resolution short-time frequency transform method has a T-F resolution problem based on the uncertainty principle, not only the short-time frequency transform but also the length of the windowing function should be optimized. To overcome this problem, we incorporate AWS into the speech enhancement procedure, and the windowing function of each time-frame is manipulated using a DNN depending on the input signal. We confirmed that the proposed method achieved a higher signal-to-distortion ratio than conventional speech enhancement methods in fixed-resolution frequency domains.
DNN-based Source Enhancement to Increase Objective Sound Quality Assessment Score
Oct 22, 2018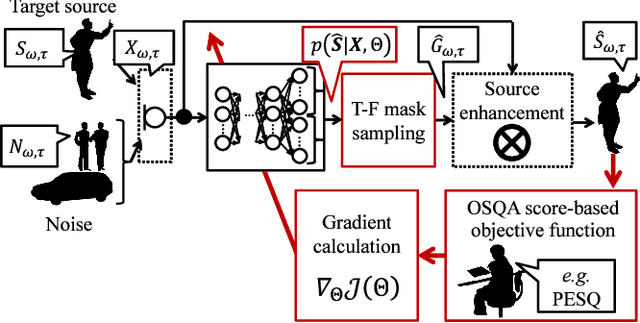

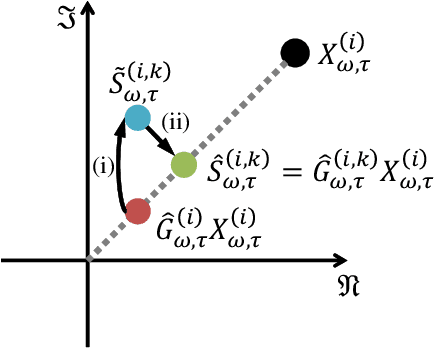
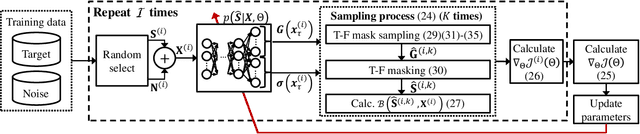
We propose a training method for deep neural network (DNN)-based source enhancement to increase objective sound quality assessment (OSQA) scores such as the perceptual evaluation of speech quality (PESQ). In many conventional studies, DNNs have been used as a mapping function to estimate time-frequency masks and trained to minimize an analytically tractable objective function such as the mean squared error (MSE). Since OSQA scores have been used widely for sound-quality evaluation, constructing DNNs to increase OSQA scores would be better than using the minimum-MSE to create high-quality output signals. However, since most OSQA scores are not analytically tractable, \textit{i.e.}, they are black boxes, the gradient of the objective function cannot be calculated by simply applying back-propagation. To calculate the gradient of the OSQA-based objective function, we formulated a DNN optimization scheme on the basis of \textit{black-box optimization}, which is used for training a computer that plays a game. For a black-box-optimization scheme, we adopt the policy gradient method for calculating the gradient on the basis of a sampling algorithm. To simulate output signals using the sampling algorithm, DNNs are used to estimate the probability density function of the output signals that maximize OSQA scores. The OSQA scores are calculated from the simulated output signals, and the DNNs are trained to increase the probability of generating the simulated output signals that achieve high OSQA scores. Through several experiments, we found that OSQA scores significantly increased by applying the proposed method, even though the MSE was not minimized.