 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhance Gender and Identity Preservation in Face Aging Simulation for Infants and Toddlers
Nov 15, 2020
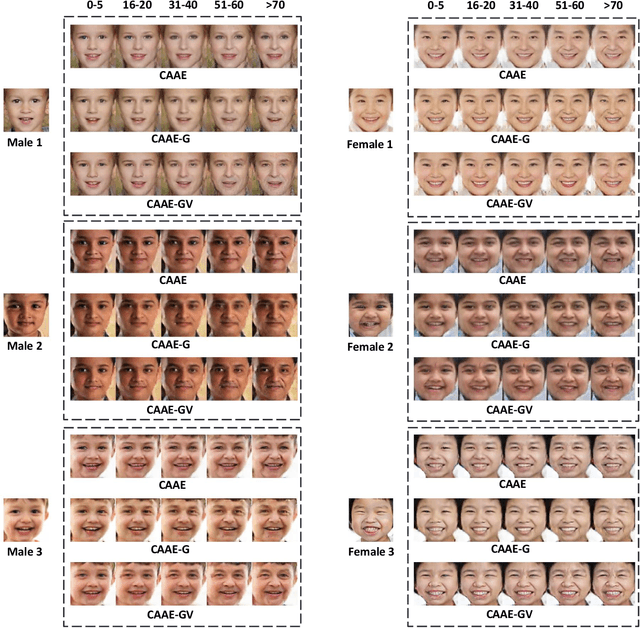


Realistic age-progressed photos provide invaluable biometric information in a wide range of applications. In recent years, deep learning-based approaches have made remarkable progress in modeling the aging process of the human face. Nevertheless, it remains a challenging task to generate accurate age-progressed faces from infant or toddler photos. In particular, the lack of visually detectable gender characteristics and the drastic appearance changes in early life contribute to the difficulty of the task. We propose a new deep learning method inspired by the successful Conditional Adversarial Autoencoder (CAAE, 2017) model. In our approach, we extend the CAAE architecture to 1) incorporate gender information, and 2) augment the model's overall architecture with an identity-preserving component based on facial features. We trained our model using the publicly available UTKFace dataset and evaluated our model by simulating up to 100 years of aging on 1,156 male and 1,207 female infant and toddler face photos. Compared to the CAAE approach, our new model demonstrates noticeable visual improvements. Quantitatively, our model exhibits an overall gain of 77.0% (male) and 13.8% (female) in gender fidelity measured by a gender classifier for the simulated photos across the age spectrum. Our model also demonstrates a 22.4% gain in identity preservation measured by a facial recognition neural network.
Localized Motion Artifact Reduction on Brain MRI Using Deep Learning with Effective Data Augmentation Techniques
Jul 10, 2020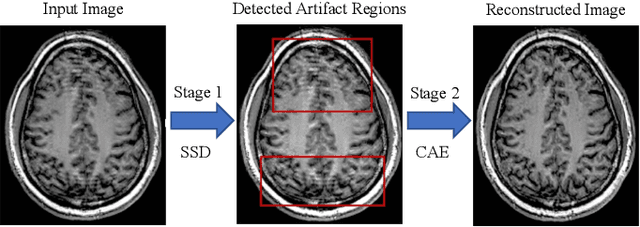
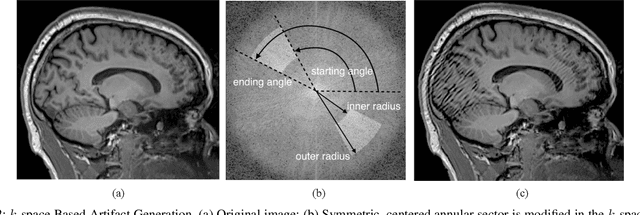
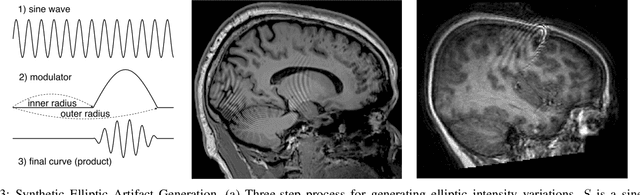
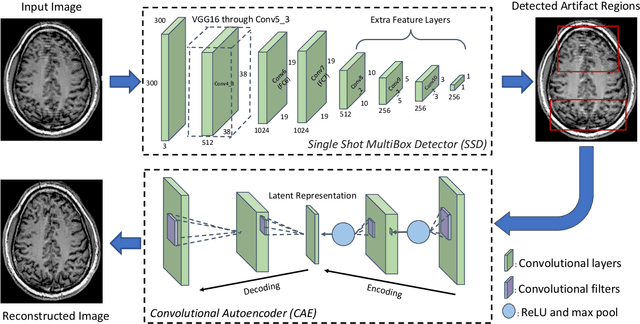
In-scanner motion degrades the quality of magnetic resonance imaging (MRI) thereby reducing its utility in the detection of clinically relevant abnormalities. We introduce a deep learning-based MRI artifact reduction model (DMAR) to localize and correct head motion artifacts in brain MRI scans. Our approach integrates the latest advances in object detection and noise reduction in Computer Vision. Specifically, DMAR employs a two-stage approach: in the first, degraded regions are detected using the Single Shot Multibox Detector (SSD), and in the second, the artifacts within the found regions are reduced using a convolutional autoencoder (CAE). We further introduce a set of novel data augmentation techniques to address the high dimensionality of MRI images and the scarcity of available data. As a result, our model was trained on a large synthetic dataset of 217,000 images generated from six whole-brain T1-weighted MRI scans obtained from three subjects. DMAR produces convincing visual results when applied to both synthetic test images and 55 real-world motion-affected slices from 18 subjects from the multi-center Autism Brain Imaging Data Exchange study. Quantitatively, depending on the level of degradation, our model achieves a 14.3%-25.6% reduction in RMSE and a 1.38-2.68 dB gain in PSNR on a 5000-sample set of synthetic images. For real-world scans where the ground-truth is unavailable, our model produces a 3.65% reduction in regional standard deviations of image intensity.