 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFBI: Learning Dexterous In-hand Manipulation with Dynamic Visuotactile Shortcut Policy
Aug 20, 2025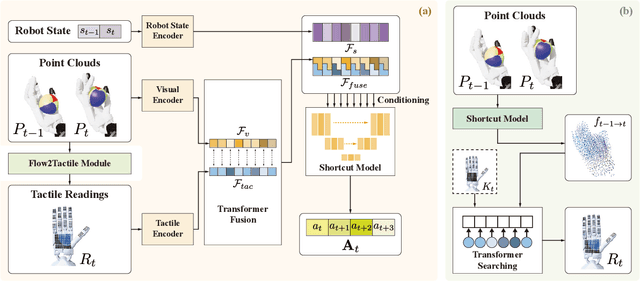


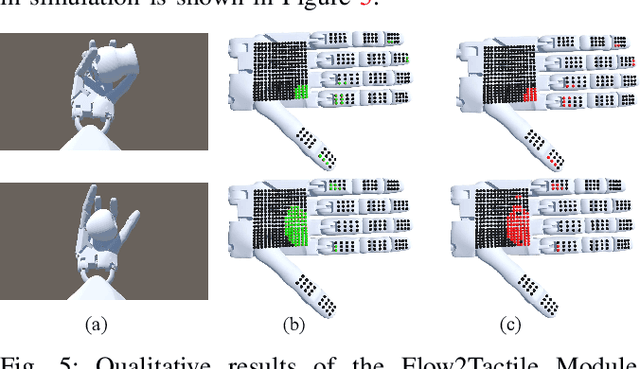
Dexterous in-hand manipulation is a long-standing challenge in robotics due to complex contact dynamics and partial observability. While humans synergize vision and touch for such tasks, robotic approaches often prioritize one modality, therefore limiting adaptability. This paper introduces Flow Before Imitation (FBI), a visuotactile imitation learning framework that dynamically fuses tactile interactions with visual observations through motion dynamics. Unlike prior static fusion methods, FBI establishes a causal link between tactile signals and object motion via a dynamics-aware latent model. FBI employs a transformer-based interaction module to fuse flow-derived tactile features with visual inputs, training a one-step diffusion policy for real-time execution. Extensive experiments demonstrate that the proposed method outperforms the baseline methods in both simulation and the real world on two customized in-hand manipulation tasks and three standard dexterous manipulation tasks. Code, models, and more results are available in the website https://sites.google.com/view/dex-fbi.
Investigating Multi-Hop Factual Shortcuts in Knowledge Editing of Large Language Models
Feb 19, 2024Recent work has showcased the powerful capability of large language models (LLMs) in recalling knowledge and reasoning. However, the reliability of LLMs in combining these two capabilities into reasoning through multi-hop facts has not been widely explored. This paper systematically investigates the possibilities for LLMs to utilize shortcuts based on direct connections between the initial and terminal entities of multi-hop knowledge. We first explore the existence of factual shortcuts through Knowledge Neurons, revealing that: (i) the strength of factual shortcuts is highly correlated with the frequency of co-occurrence of initial and terminal entities in the pre-training corpora; (ii) few-shot prompting leverage more shortcuts in answering multi-hop questions compared to chain-of-thought prompting. Then, we analyze the risks posed by factual shortcuts from the perspective of multi-hop knowledge editing. Analysis shows that approximately 20% of the failures are attributed to shortcuts, and the initial and terminal entities in these failure instances usually have higher co-occurrences in the pre-training corpus. Finally, we propose erasing shortcut neurons to mitigate the associated risks and find that this approach significantly reduces failures in multiple-hop knowledge editing caused by shortcuts.
STFAR: Improving Object Detection Robustness at Test-Time by Self-Training with Feature Alignment Regularization
Mar 31, 2023Domain adaptation helps generalizing object detection models to target domain data with distribution shift. It is often achieved by adapting with access to the whole target domain data. In a more realistic scenario, target distribution is often unpredictable until inference stage. This motivates us to explore adapting an object detection model at test-time, a.k.a. test-time adaptation (TTA). In this work, we approach test-time adaptive object detection (TTAOD) from two perspective. First, we adopt a self-training paradigm to generate pseudo labeled objects with an exponential moving average model. The pseudo labels are further used to supervise adapting source domain model. As self-training is prone to incorrect pseudo labels, we further incorporate aligning feature distributions at two output levels as regularizations to self-training. To validate the performance on TTAOD, we create benchmarks based on three standard object detection datasets and adapt generic TTA methods to object detection task. Extensive evaluations suggest our proposed method sets the state-of-the-art on test-time adaptive object detection task.