 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Agents for Automated Confounder Discovery and Subgroup Analysis in Causal Inference
Aug 10, 2025Estimating individualized treatment effects from observational data presents a persistent challenge due to unmeasured confounding and structural bias. Causal Machine Learning (causal ML) methods, such as causal trees and doubly robust estimators, provide tools for estimating conditional average treatment effects. These methods have limited effectiveness in complex real-world environments due to the presence of latent confounders or those described in unstructured formats. Moreover, reliance on domain experts for confounder identification and rule interpretation introduces high annotation cost and scalability concerns. In this work, we proposed Large Language Model-based agents for automated confounder discovery and subgroup analysis that integrate agents into the causal ML pipeline to simulate domain expertise. Our framework systematically performs subgroup identification and confounding structure discovery by leveraging the reasoning capabilities of LLM-based agents, which reduces human dependency while preserving interpretability. Experiments on real-world medical datasets show that our proposed approach enhances treatment effect estimation robustness by narrowing confidence intervals and uncovering unrecognized confounding biases. Our findings suggest that LLM-based agents offer a promising path toward scalable, trustworthy, and semantically aware causal inference.
Towards Simulating Social Influence Dynamics with LLM-based Multi-agents
Jul 30, 2025Recent advancements in Large Language Models offer promising capabilities to simulate complex human social interactions. We investigate whether LLM-based multi-agent simulations can reproduce core human social dynamics observed in online forums. We evaluate conformity dynamics, group polarization, and fragmentation across different model scales and reasoning capabilities using a structured simulation framework. Our findings indicate that smaller models exhibit higher conformity rates, whereas models optimized for reasoning are more resistant to social influence.
Towards Interpretable Renal Health Decline Forecasting via Multi-LMM Collaborative Reasoning Framework
Jul 30, 2025Accurate and interpretable prediction of estimated glomerular filtration rate (eGFR) is essential for managing chronic kidney disease (CKD) and supporting clinical decisions. Recent advances in Large Multimodal Models (LMMs) have shown strong potential in clinical prediction tasks due to their ability to process visual and textual information. However, challenges related to deployment cost, data privacy, and model reliability hinder their adoption. In this study, we propose a collaborative framework that enhances the performance of open-source LMMs for eGFR forecasting while generating clinically meaningful explanations. The framework incorporates visual knowledge transfer, abductive reasoning, and a short-term memory mechanism to enhance prediction accuracy and interpretability. Experimental results show that the proposed framework achieves predictive performance and interpretability comparable to proprietary models. It also provides plausible clinical reasoning processes behind each prediction. Our method sheds new light on building AI systems for healthcare that combine predictive accuracy with clinically grounded interpretability.
Understanding eGFR Trajectories and Kidney Function Decline via Large Multimodal Models
Sep 04, 2024
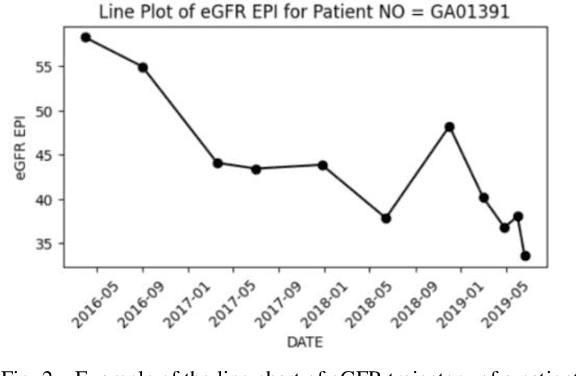


The estimated Glomerular Filtration Rate (eGFR) is an essential indicator of kidney function in clinical practice. Although traditional equations and Machine Learning (ML) models using clinical and laboratory data can estimate eGFR, accurately predicting future eGFR levels remains a significant challenge for nephrologists and ML researchers. Recent advances demonstrate that Large Language Models (LLMs) and Large Multimodal Models (LMMs) can serve as robust foundation models for diverse applications. This study investigates the potential of LMMs to predict future eGFR levels with a dataset consisting of laboratory and clinical values from 50 patients. By integrating various prompting techniques and ensembles of LMMs, our findings suggest that these models, when combined with precise prompts and visual representations of eGFR trajectories, offer predictive performance comparable to existing ML models. This research extends the application of foundation models and suggests avenues for future studies to harness these models in addressing complex medical forecasting challenges.
Subgroup Analysis via Model-based Rule Forest
Aug 27, 2024



Machine learning models are often criticized for their black-box nature, raising concerns about their applicability in critical decision-making scenarios. Consequently, there is a growing demand for interpretable models in such contexts. In this study, we introduce Model-based Deep Rule Forests (mobDRF), an interpretable representation learning algorithm designed to extract transparent models from data. By leveraging IF-THEN rules with multi-level logic expressions, mobDRF enhances the interpretability of existing models without compromising accuracy. We apply mobDRF to identify key risk factors for cognitive decline in an elderly population, demonstrating its effectiveness in subgroup analysis and local model optimization. Our method offers a promising solution for developing trustworthy and interpretable machine learning models, particularly valuable in fields like healthcare, where understanding differential effects across patient subgroups can lead to more personalized and effective treatments.
Causal Rule Forest: Toward Interpretable and Precise Treatment Effect Estimation
Aug 27, 2024Understanding and inferencing Heterogeneous Treatment Effects (HTE) and Conditional Average Treatment Effects (CATE) are vital for developing personalized treatment recommendations. Many state-of-the-art approaches achieve inspiring performance in estimating HTE on benchmark datasets or simulation studies. However, the indirect predicting manner and complex model architecture reduce the interpretability of these approaches. To mitigate the gap between predictive performance and heterogeneity interpretability, we introduce the Causal Rule Forest (CRF), a novel approach to learning hidden patterns from data and transforming the patterns into interpretable multi-level Boolean rules. By training the other interpretable causal inference models with data representation learned by CRF, we can reduce the predictive errors of these models in estimating HTE and CATE, while keeping their interpretability for identifying subgroups that a treatment is more effective. Our experiments underscore the potential of CRF to advance personalized interventions and policies, paving the way for future research to enhance its scalability and application across complex causal inference challenges.
Toward Transparent Sequence Models with Model-Based Tree Markov Model
Jul 28, 2023



In this study, we address the interpretability issue in complex, black-box Machine Learning models applied to sequence data. We introduce the Model-Based tree Hidden Semi-Markov Model (MOB-HSMM), an inherently interpretable model aimed at detecting high mortality risk events and discovering hidden patterns associated with the mortality risk in Intensive Care Units (ICU). This model leverages knowledge distilled from Deep Neural Networks (DNN) to enhance predictive performance while offering clear explanations. Our experimental results indicate the improved performance of Model-Based trees (MOB trees) via employing LSTM for learning sequential patterns, which are then transferred to MOB trees. Integrating MOB trees with the Hidden Semi-Markov Model (HSMM) in the MOB-HSMM enables uncovering potential and explainable sequences using available information.
Towards Model-informed Precision Dosing with Expert-in-the-loop Machine Learning
Jun 29, 2021



Machine Learning (ML) and its applications have been transforming our lives but it is also creating issues related to the development of fair, accountable, transparent, and ethical Artificial Intelligence. As the ML models are not fully comprehensible yet, it is obvious that we still need humans to be part of algorithmic decision-making processes. In this paper, we consider a ML framework that may accelerate model learning and improve its interpretability by incorporating human experts into the model learning loop. We propose a novel human-in-the-loop ML framework aimed at dealing with learning problems that the cost of data annotation is high and the lack of appropriate data to model the association between the target tasks and the input features. With an application to precision dosing, our experimental results show that the approach can learn interpretable rules from data and may potentially lower experts' workload by replacing data annotation with rule representation editing. The approach may also help remove algorithmic bias by introducing experts' feedback into the iterative model learning process.
Topic Diffusion Discovery Based on Deep Non-negative Autoencoder
Oct 08, 2020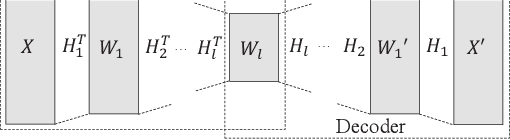


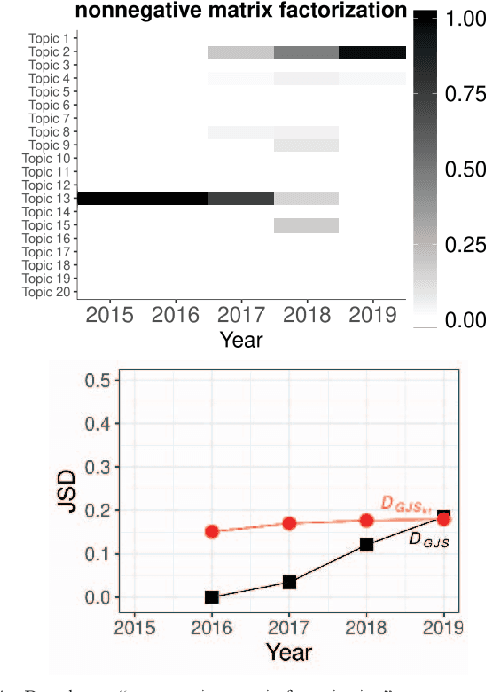
Researchers have been overwhelmed by the explosion of research articles published by various research communities. Many research scholarly websites, search engines, and digital libraries have been created to help researchers identify potential research topics and keep up with recent progress on research of interests. However, it is still difficult for researchers to keep track of the research topic diffusion and evolution without spending a large amount of time reviewing numerous relevant and irrelevant articles. In this paper, we consider a novel topic diffusion discovery technique. Specifically, we propose using a Deep Non-negative Autoencoder with information divergence measurement that monitors evolutionary distance of the topic diffusion to understand how research topics change with time. The experimental results show that the proposed approach is able to identify the evolution of research topics as well as to discover topic diffusions in online fashions.
Discovering Drug-Drug and Drug-Disease Interactions Inducing Acute Kidney Injury Using Deep Rule Forests
Jul 04, 2020
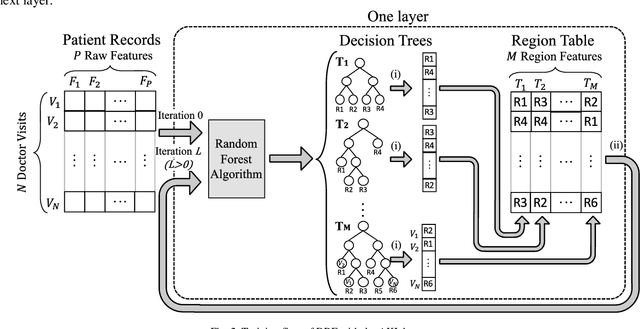

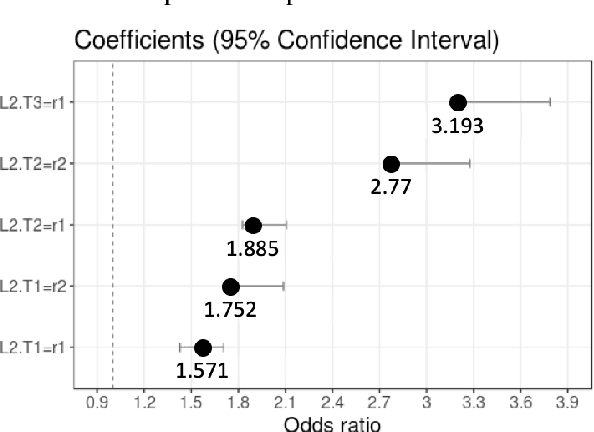
Patients with Acute Kidney Injury (AKI) increase mortality, morbidity, and long-term adverse events. Therefore, early identification of AKI may improve renal function recovery, decrease comorbidities, and further improve patients' survival. To control certain risk factors and develop targeted prevention strategies are important to reduce the risk of AKI. Drug-drug interactions and drug-disease interactions are critical issues for AKI. Typical statistical approaches cannot handle the complexity of drug-drug and drug-disease interactions. In this paper, we propose a novel learning algorithm, Deep Rule Forests (DRF), which discovers rules from multilayer tree models as the combinations of drug usages and disease indications to help identify such interactions. We found that several disease and drug usages are considered having significant impact on the occurrence of AKI. Our experimental results also show that the DRF model performs comparatively better than typical tree-based and other state-of-the-art algorithms in terms of prediction accuracy and model interpretability.