 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding eGFR Trajectories and Kidney Function Decline via Large Multimodal Models
Sep 04, 2024
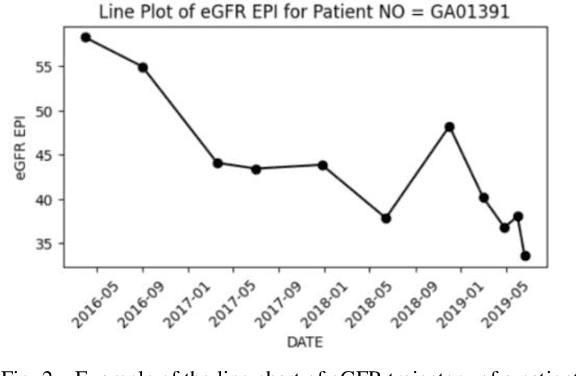


The estimated Glomerular Filtration Rate (eGFR) is an essential indicator of kidney function in clinical practice. Although traditional equations and Machine Learning (ML) models using clinical and laboratory data can estimate eGFR, accurately predicting future eGFR levels remains a significant challenge for nephrologists and ML researchers. Recent advances demonstrate that Large Language Models (LLMs) and Large Multimodal Models (LMMs) can serve as robust foundation models for diverse applications. This study investigates the potential of LMMs to predict future eGFR levels with a dataset consisting of laboratory and clinical values from 50 patients. By integrating various prompting techniques and ensembles of LMMs, our findings suggest that these models, when combined with precise prompts and visual representations of eGFR trajectories, offer predictive performance comparable to existing ML models. This research extends the application of foundation models and suggests avenues for future studies to harness these models in addressing complex medical forecasting challenges.
Toward Transparent Sequence Models with Model-Based Tree Markov Model
Jul 28, 2023



In this study, we address the interpretability issue in complex, black-box Machine Learning models applied to sequence data. We introduce the Model-Based tree Hidden Semi-Markov Model (MOB-HSMM), an inherently interpretable model aimed at detecting high mortality risk events and discovering hidden patterns associated with the mortality risk in Intensive Care Units (ICU). This model leverages knowledge distilled from Deep Neural Networks (DNN) to enhance predictive performance while offering clear explanations. Our experimental results indicate the improved performance of Model-Based trees (MOB trees) via employing LSTM for learning sequential patterns, which are then transferred to MOB trees. Integrating MOB trees with the Hidden Semi-Markov Model (HSMM) in the MOB-HSMM enables uncovering potential and explainable sequences using available information.
Fake News Detection and Behavioral Analysis: Case of COVID-19
May 25, 2023



While the world has been combating COVID-19 for over three years, an ongoing "Infodemic" due to the spread of fake news regarding the pandemic has also been a global issue. The existence of the fake news impact different aspect of our daily lives, including politics, public health, economic activities, etc. Readers could mistake fake news for real news, and consequently have less access to authentic information. This phenomenon will likely cause confusion of citizens and conflicts in society. Currently, there are major challenges in fake news research. It is challenging to accurately identify fake news data in social media posts. In-time human identification is infeasible as the amount of the fake news data is overwhelming. Besides, topics discussed in fake news are hard to identify due to their similarity to real news. The goal of this paper is to identify fake news on social media to help stop the spread. We present Deep Learning approaches and an ensemble approach for fake news detection. Our detection models achieved higher accuracy than previous studies. The ensemble approach further improved the detection performance. We discovered feature differences between fake news and real news items. When we added them into the sentence embeddings, we found that they affected the model performance. We applied a hybrid method and built models for recognizing topics from posts. We found half of the identified topics were overlapping in fake news and real news, which could increase confusion in the population.