 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interpretable Renal Health Decline Forecasting via Multi-LMM Collaborative Reasoning Framework
Jul 30, 2025Accurate and interpretable prediction of estimated glomerular filtration rate (eGFR) is essential for managing chronic kidney disease (CKD) and supporting clinical decisions. Recent advances in Large Multimodal Models (LMMs) have shown strong potential in clinical prediction tasks due to their ability to process visual and textual information. However, challenges related to deployment cost, data privacy, and model reliability hinder their adoption. In this study, we propose a collaborative framework that enhances the performance of open-source LMMs for eGFR forecasting while generating clinically meaningful explanations. The framework incorporates visual knowledge transfer, abductive reasoning, and a short-term memory mechanism to enhance prediction accuracy and interpretability. Experimental results show that the proposed framework achieves predictive performance and interpretability comparable to proprietary models. It also provides plausible clinical reasoning processes behind each prediction. Our method sheds new light on building AI systems for healthcare that combine predictive accuracy with clinically grounded interpretability.
Understanding eGFR Trajectories and Kidney Function Decline via Large Multimodal Models
Sep 04, 2024
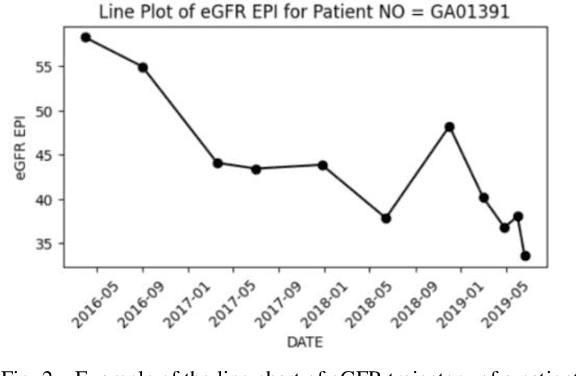


The estimated Glomerular Filtration Rate (eGFR) is an essential indicator of kidney function in clinical practice. Although traditional equations and Machine Learning (ML) models using clinical and laboratory data can estimate eGFR, accurately predicting future eGFR levels remains a significant challenge for nephrologists and ML researchers. Recent advances demonstrate that Large Language Models (LLMs) and Large Multimodal Models (LMMs) can serve as robust foundation models for diverse applications. This study investigates the potential of LMMs to predict future eGFR levels with a dataset consisting of laboratory and clinical values from 50 patients. By integrating various prompting techniques and ensembles of LMMs, our findings suggest that these models, when combined with precise prompts and visual representations of eGFR trajectories, offer predictive performance comparable to existing ML models. This research extends the application of foundation models and suggests avenues for future studies to harness these models in addressing complex medical forecasting challenges.
Towards Model-informed Precision Dosing with Expert-in-the-loop Machine Learning
Jun 29, 2021



Machine Learning (ML) and its applications have been transforming our lives but it is also creating issues related to the development of fair, accountable, transparent, and ethical Artificial Intelligence. As the ML models are not fully comprehensible yet, it is obvious that we still need humans to be part of algorithmic decision-making processes. In this paper, we consider a ML framework that may accelerate model learning and improve its interpretability by incorporating human experts into the model learning loop. We propose a novel human-in-the-loop ML framework aimed at dealing with learning problems that the cost of data annotation is high and the lack of appropriate data to model the association between the target tasks and the input features. With an application to precision dosing, our experimental results show that the approach can learn interpretable rules from data and may potentially lower experts' workload by replacing data annotation with rule representation editing. The approach may also help remove algorithmic bias by introducing experts' feedback into the iterative model learning process.