 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025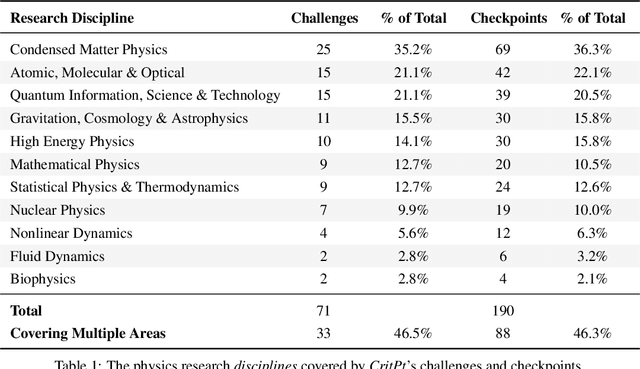
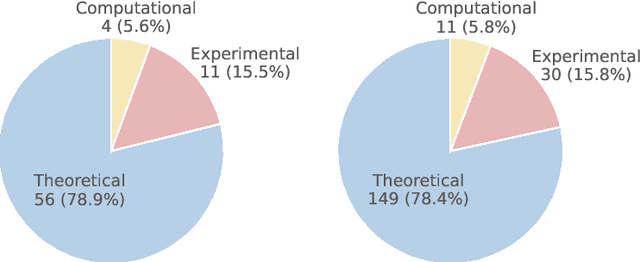
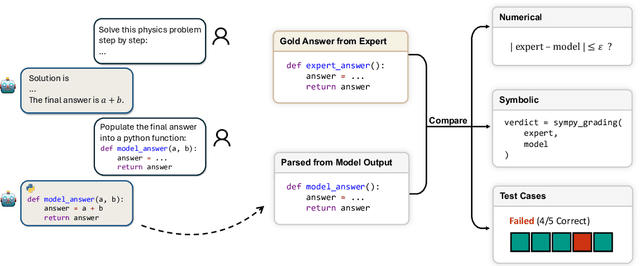

While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
BTPG-max: Achieving Local Maximal Bidirectional Pairs for Bidirectional Temporal Plan Graphs
Aug 06, 2025Multi-Agent Path Finding (MAPF) requires computing collision-free paths for multiple agents in shared environment. Most MAPF planners assume that each agent reaches a specific location at a specific timestep, but this is infeasible to directly follow on real systems where delays often occur. To address collisions caused by agents deviating due to delays, the Temporal Plan Graph (TPG) was proposed, which converts a MAPF time dependent solution into a time independent set of inter-agent dependencies. Recently, a Bidirectional TPG (BTPG) was proposed which relaxed some dependencies into ``bidirectional pairs" and improved efficiency of agents executing their MAPF solution with delays. Our work improves upon this prior work by designing an algorithm, BPTG-max, that finds more bidirectional pairs. Our main theoretical contribution is in designing the BTPG-max algorithm is locally optimal, i.e. which constructs a BTPG where no additional bidirectional pairs can be added. We also show how in practice BTPG-max leads to BTPGs with significantly more bidirectional edges, superior anytime behavior, and improves robustness to delays.
Evolutionary Policy Optimization
Mar 24, 2025



Despite its extreme sample inefficiency, on-policy reinforcement learning has become a fundamental tool in real-world applications. With recent advances in GPU-driven simulation, the ability to collect vast amounts of data for RL training has scaled exponentially. However, studies show that current on-policy methods, such as PPO, fail to fully leverage the benefits of parallelized environments, leading to performance saturation beyond a certain scale. In contrast, Evolutionary Algorithms (EAs) excel at increasing diversity through randomization, making them a natural complement to RL. However, existing EvoRL methods have struggled to gain widespread adoption due to their extreme sample inefficiency. To address these challenges, we introduce Evolutionary Policy Optimization (EPO), a novel policy gradient algorithm that combines the strengths of EA and policy gradients. We show that EPO significantly improves performance across diverse and challenging environments, demonstrating superior scalability with parallelized simulations.
Bidirectional Temporal Plan Graph: Enabling Switchable Passing Orders for More Efficient Multi-Agent Path Finding Plan Execution
Jan 07, 2024



The Multi-Agent Path Finding (MAPF) problem involves planning collision-free paths for multiple agents in a shared environment. The majority of MAPF solvers rely on the assumption that an agent can arrive at a specific location at a specific timestep. However, real-world execution uncertainties can cause agents to deviate from this assumption, leading to collisions and deadlocks. Prior research solves this problem by having agents follow a Temporal Plan Graph (TPG), enforcing a consistent passing order at every location as defined in the MAPF plan. However, we show that TPGs are overly strict because, in some circumstances, satisfying the passing order requires agents to wait unnecessarily, leading to longer execution time. To overcome this issue, we introduce a new graphical representation called a Bidirectional Temporal Plan Graph (BTPG), which allows switching passing orders during execution to avoid unnecessary waiting time. We design two anytime algorithms for constructing a BTPG: BTPG-na\"ive and BTPG-optimized. Experimental results show that following BTPGs consistently outperforms following TPGs, reducing unnecessary waits by 8-20%.