 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Differential Evolution based Feature Selection through Quantum, Chaos, and Lasso
Aug 20, 2024Modern deep learning continues to achieve outstanding performance on an astounding variety of high-dimensional tasks. In practice, this is obtained by fitting deep neural models to all the input data with minimal feature engineering, thus sacrificing interpretability in many cases. However, in applications such as medicine, where interpretability is crucial, feature subset selection becomes an important problem. Metaheuristics such as Binary Differential Evolution are a popular approach to feature selection, and the research literature continues to introduce novel ideas, drawn from quantum computing and chaos theory, for instance, to improve them. In this paper, we demonstrate that introducing chaos-generated variables, generated from considerations of the Lyapunov time, in place of random variables in quantum-inspired metaheuristics significantly improves their performance on high-dimensional medical classification tasks and outperforms other approaches. We show that this chaos-induced improvement is a general phenomenon by demonstrating it for multiple varieties of underlying quantum-inspired metaheuristics. Performance is further enhanced through Lasso-assisted feature pruning. At the implementation level, we vastly speed up our algorithms through a scalable island-based computing cluster parallelization technique.
Quantum-Inspired Evolutionary Algorithms for Feature Subset Selection: A Comprehensive Survey
Jul 25, 2024



The clever hybridization of quantum computing concepts and evolutionary algorithms (EAs) resulted in a new field called quantum-inspired evolutionary algorithms (QIEAs). Unlike traditional EAs, QIEAs employ quantum bits to adopt a probabilistic representation of the state of a feature in a given solution. This unprecedented feature enables them to achieve better diversity and perform global search, effectively yielding a tradeoff between exploration and exploitation. We conducted a comprehensive survey across various publishers and gathered 56 papers. We thoroughly analyzed these publications, focusing on the novelty elements and types of heuristics employed by the extant quantum-inspired evolutionary algorithms (QIEAs) proposed to solve the feature subset selection (FSS) problem. Importantly, we provided a detailed analysis of the different types of objective functions and popular quantum gates, i.e., rotation gates, employed throughout the literature. Additionally, we suggested several open research problems to attract the attention of the researchers.
Causal Inference for Banking Finance and Insurance A Survey
Jul 31, 2023Causal Inference plays an significant role in explaining the decisions taken by statistical models and artificial intelligence models. Of late, this field started attracting the attention of researchers and practitioners alike. This paper presents a comprehensive survey of 37 papers published during 1992-2023 and concerning the application of causal inference to banking, finance, and insurance. The papers are categorized according to the following families of domains: (i) Banking, (ii) Finance and its subdomains such as corporate finance, governance finance including financial risk and financial policy, financial economics, and Behavioral finance, and (iii) Insurance. Further, the paper covers the primary ingredients of causal inference namely, statistical methods such as Bayesian Causal Network, Granger Causality and jargon used thereof such as counterfactuals. The review also recommends some important directions for future research. In conclusion, we observed that the application of causal inference in the banking and insurance sectors is still in its infancy, and thus more research is possible to turn it into a viable method.
FedPNN: One-shot Federated Classification via Evolving Clustering Method and Probabilistic Neural Network hybrid
Apr 09, 2023Protecting data privacy is paramount in the fields such as finance, banking, and healthcare. Federated Learning (FL) has attracted widespread attention due to its decentralized, distributed training and the ability to protect the privacy while obtaining a global shared model. However, FL presents challenges such as communication overhead, and limited resource capability. This motivated us to propose a two-stage federated learning approach toward the objective of privacy protection, which is a first-of-its-kind study as follows: (i) During the first stage, the synthetic dataset is generated by employing two different distributions as noise to the vanilla conditional tabular generative adversarial neural network (CTGAN) resulting in modified CTGAN, and (ii) In the second stage, the Federated Probabilistic Neural Network (FedPNN) is developed and employed for building globally shared classification model. We also employed synthetic dataset metrics to check the quality of the generated synthetic dataset. Further, we proposed a meta-clustering algorithm whereby the cluster centers obtained from the clients are clustered at the server for training the global model. Despite PNN being a one-pass learning classifier, its complexity depends on the training data size. Therefore, we employed a modified evolving clustering method (ECM), another one-pass algorithm to cluster the training data thereby increasing the speed further. Moreover, we conducted sensitivity analysis by varying Dthr, a hyperparameter of ECM at the server and client, one at a time. The effectiveness of our approach is validated on four finance and medical datasets.
ATM Fraud Detection using Streaming Data Analytics
Mar 08, 2023



Gaining the trust and confidence of customers is the essence of the growth and success of financial institutions and organizations. Of late, the financial industry is significantly impacted by numerous instances of fraudulent activities. Further, owing to the generation of large voluminous datasets, it is highly essential that underlying framework is scalable and meet real time needs. To address this issue, in the study, we proposed ATM fraud detection in static and streaming contexts respectively. In the static context, we investigated a parallel and scalable machine learning algorithms for ATM fraud detection that is built on Spark and trained with a variety of machine learning (ML) models including Naive Bayes (NB), Logistic Regression (LR), Support Vector Machine (SVM), Decision Tree (DT), Random Forest (RF), Gradient Boosting Tree (GBT), and Multi-layer perceptron (MLP). We also employed several balancing techniques like Synthetic Minority Oversampling Technique (SMOTE) and its variants, Generative Adversarial Networks (GAN), to address the rarity in the dataset. In addition, we proposed a streaming based ATM fraud detection in the streaming context. Our sliding window based method collects ATM transactions that are performed within a specified time interval and then utilizes to train several ML models, including NB, RF, DT, and K-Nearest Neighbour (KNN). We selected these models based on their less model complexity and quicker response time. In both contexts, RF turned out to be the best model. RF obtained the best mean AUC of 0.975 in the static context and mean AUC of 0.910 in the streaming context. RF is also empirically proven to be statistically significant than the next-best performing models.
Chaotic Variational Auto encoder-based Adversarial Machine Learning
Feb 25, 2023Machine Learning (ML) has become the new contrivance in almost every field. This makes them a target of fraudsters by various adversary attacks, thereby hindering the performance of ML models. Evasion and Data-Poison-based attacks are well acclaimed, especially in finance, healthcare, etc. This motivated us to propose a novel computationally less expensive attack mechanism based on the adversarial sample generation by Variational Auto Encoder (VAE). It is well known that Wavelet Neural Network (WNN) is considered computationally efficient in solving image and audio processing, speech recognition, and time-series forecasting. This paper proposed VAE-Deep-Wavelet Neural Network (VAE-Deep-WNN), where Encoder and Decoder employ WNN networks. Further, we proposed chaotic variants of both VAE with Multi-layer perceptron (MLP) and Deep-WNN and named them C-VAE-MLP and C-VAE-Deep-WNN, respectively. Here, we employed a Logistic map to generate random noise in the latent space. In this paper, we performed VAE-based adversary sample generation and applied it to various problems related to finance and cybersecurity domain-related problems such as loan default, credit card fraud, and churn modelling, etc., We performed both Evasion and Data-Poison attacks on Logistic Regression (LR) and Decision Tree (DT) models. The results indicated that VAE-Deep-WNN outperformed the rest in the majority of the datasets and models. However, its chaotic variant C-VAE-Deep-WNN performed almost similarly to VAE-Deep-WNN in the majority of the datasets.
Chaotic Variational Auto Encoder based One Class Classifier for Insurance Fraud Detection
Dec 15, 2022



Of late, insurance fraud detection has assumed immense significance owing to the huge financial & reputational losses fraud entails and the phenomenal success of the fraud detection techniques. Insurance is majorly divided into two categories: (i) Life and (ii) Non-life. Non-life insurance in turn includes health insurance and auto insurance among other things. In either of the categories, the fraud detection techniques should be designed in such a way that they capture as many fraudulent transactions as possible. Owing to the rarity of fraudulent transactions, in this paper, we propose a chaotic variational autoencoder (C-VAE to perform one-class classification (OCC) on genuine transactions. Here, we employed the logistic chaotic map to generate random noise in the latent space. The effectiveness of C-VAE is demonstrated on the health insurance fraud and auto insurance datasets. We considered vanilla Variational Auto Encoder (VAE) as the baseline. It is observed that C-VAE outperformed VAE in both datasets. C-VAE achieved a classification rate of 77.9% and 87.25% in health and automobile insurance datasets respectively. Further, the t-test conducted at 1% level of significance and 18 degrees of freedom infers that C-VAE is statistically significant than the VAE.
Explainable Artificial Intelligence and Causal Inference based ATM Fraud Detection
Nov 19, 2022


Gaining the trust of customers and providing them empathy are very critical in the financial domain. Frequent occurrence of fraudulent activities affects these two factors. Hence, financial organizations and banks must take utmost care to mitigate them. Among them, ATM fraudulent transaction is a common problem faced by banks. There following are the critical challenges involved in fraud datasets: the dataset is highly imbalanced, the fraud pattern is changing, etc. Owing to the rarity of fraudulent activities, Fraud detection can be formulated as either a binary classification problem or One class classification (OCC). In this study, we handled these techniques on an ATM transactions dataset collected from India. In binary classification, we investigated the effectiveness of various over-sampling techniques, such as the Synthetic Minority Oversampling Technique (SMOTE) and its variants, Generative Adversarial Networks (GAN), to achieve oversampling. Further, we employed various machine learning techniques viz., Naive Bayes (NB), Logistic Regression (LR), Support Vector Machine (SVM), Decision Tree (DT), Random Forest (RF), Gradient Boosting Tree (GBT), Multi-layer perceptron (MLP). GBT outperformed the rest of the models by achieving 0.963 AUC, and DT stands second with 0.958 AUC. DT is the winner if the complexity and interpretability aspects are considered. Among all the oversampling approaches, SMOTE and its variants were observed to perform better. In OCC, IForest attained 0.959 CR, and OCSVM secured second place with 0.947 CR. Further, we incorporated explainable artificial intelligence (XAI) and causal inference (CI) in the fraud detection framework and studied it through various analyses.
Parallel and Streaming Wavelet Neural Networks for Classification and Regression under Apache Spark
Sep 07, 2022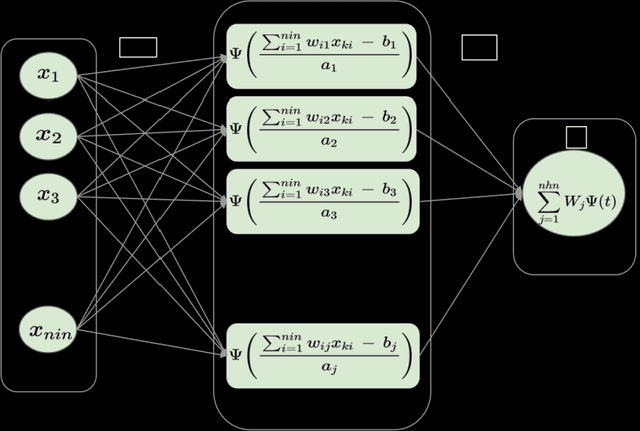
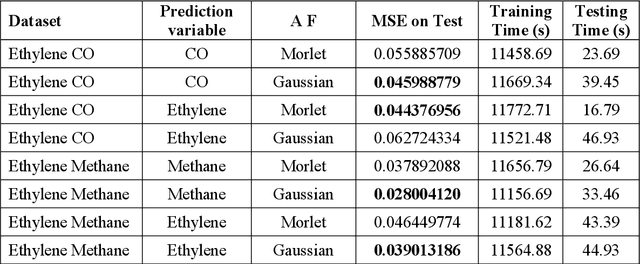

Wavelet neural networks (WNN) have been applied in many fields to solve regression as well as classification problems. After the advent of big data, as data gets generated at a brisk pace, it is imperative to analyze it as soon as it is generated owing to the fact that the nature of the data may change dramatically in short time intervals. This is necessitated by the fact that big data is all pervasive and throws computational challenges for data scientists. Therefore, in this paper, we built an efficient Scalable, Parallelized Wavelet Neural Network (SPWNN) which employs the parallel stochastic gradient algorithm (SGD) algorithm. SPWNN is designed and developed under both static and streaming environments in the horizontal parallelization framework. SPWNN is implemented by using Morlet and Gaussian functions as activation functions. This study is conducted on big datasets like gas sensor data which has more than 4 million samples and medical research data which has more than 10,000 features, which are high dimensional in nature. The experimental analysis indicates that in the static environment, SPWNN with Morlet activation function outperformed SPWNN with Gaussian on the classification datasets. However, in the case of regression, the opposite was observed. In contrast, in the streaming environment i.e., Gaussian outperformed Morlet on the classification and Morlet outperformed Gaussian on the regression datasets. Overall, the proposed SPWNN architecture achieved a speedup of 1.32-1.40.
Feature subset selection for Big Data via Chaotic Binary Differential Evolution under Apache Spark
Feb 08, 2022


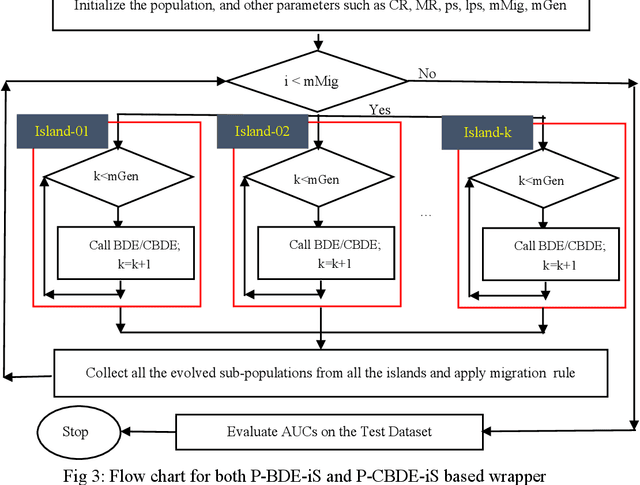
Feature subset selection (FSS) using a wrapper approach is essentially a combinatorial optimization problem having two objective functions namely cardinality of the selected-feature-subset, which should be minimized and the corresponding area under the ROC curve (AUC) to be maximized. In this research study, we propose a novel multiplicative single objective function involving cardinality and AUC. The randomness involved in the Binary Differential Evolution (BDE) may yield less diverse solutions thereby getting trapped in local minima. Hence, we embed Logistic and Tent chaotic maps into the BDE and named it as Chaotic Binary Differential Evolution (CBDE). Designing a scalable solution to the FSS is critical when dealing with high-dimensional and voluminous datasets. Hence, we propose a scalable island (iS) based parallelization approach where the data is divided into multiple partitions/islands thereby the solution evolves individually and gets combined eventually in a migration strategy. The results empirically show that the proposed parallel Chaotic Binary Differential Evolution (P-CBDE-iS) is able to find the better quality feature subsets than the Parallel Bi-nary Differential Evolution (P-BDE-iS). Logistic Regression (LR) is used as a classifier owing to its simplicity and power. The speedup attained by the proposed parallel approach signifies the importance.