 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Model Robustness with Transformation-Invariant Attacks
Jan 31, 2019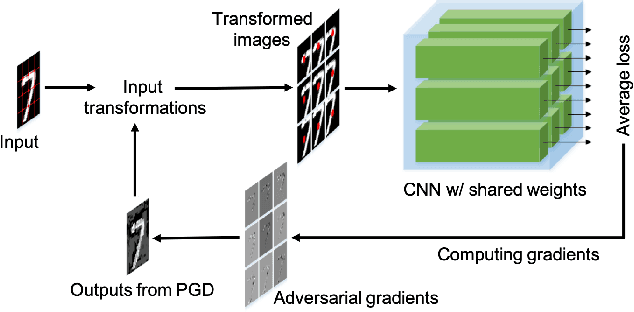

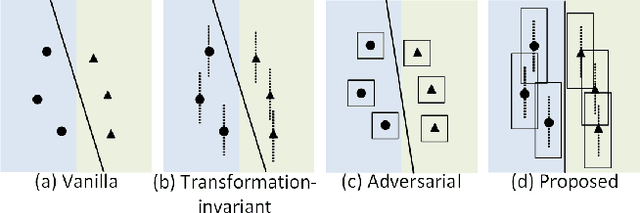
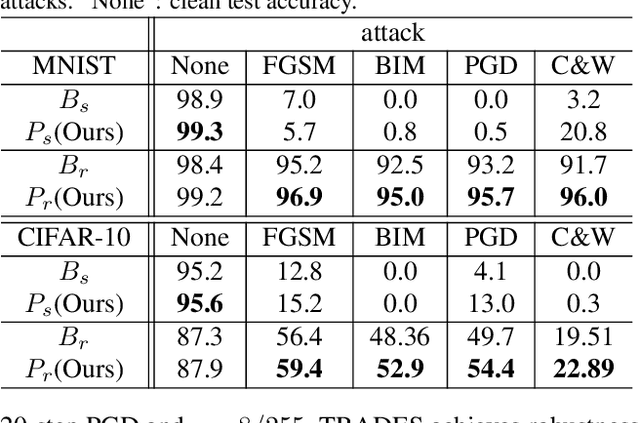
Vulnerability of neural networks under adversarial attacks has raised serious concerns and extensive research. Recent studies suggested that model robustness relies on the use of robust features, i.e., features with strong correlation with labels, and that data dimensionality and distribution affect the learning of robust features. On the other hand, experiments showed that human vision, which is robust against adversarial attacks, is invariant to natural input transformations. Drawing on these findings, this paper investigates whether constraints on transformation invariance, including image cropping, rotation, and zooming, will force image classifiers to learn and use robust features and in turn acquire better robustness. Experiments on MNIST and CIFAR10 show that transformation invariance alone has limited effect. Nonetheless, models adversarially trained on cropping-invariant attacks, in particular, can (1) extract more robust features, (2) have significantly better robustness than the state-of-the-art models from adversarial training, and (3) require less training data.