 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevign: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks
Sep 08, 2019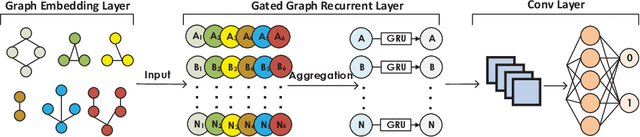
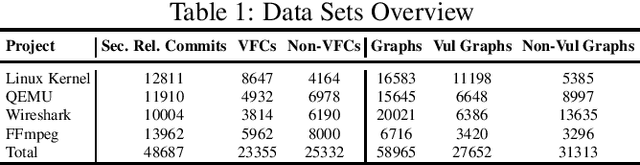
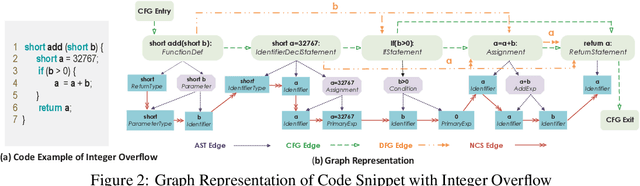
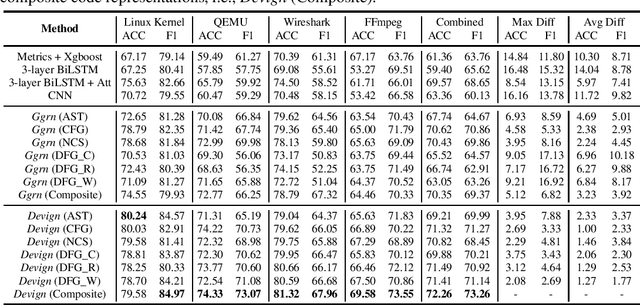
Vulnerability identification is crucial to protect the software systems from attacks for cyber security. It is especially important to localize the vulnerable functions among the source code to facilitate the fix. However, it is a challenging and tedious process, and also requires specialized security expertise. Inspired by the work on manually-defined patterns of vulnerabilities from various code representation graphs and the recent advance on graph neural networks, we propose Devign, a general graph neural network based model for graph-level classification through learning on a rich set of code semantic representations. It includes a novel Conv module to efficiently extract useful features in the learned rich node representations for graph-level classification. The model is trained over manually labeled datasets built on 4 diversified large-scale open-source C projects that incorporate high complexity and variety of real source code instead of synthesis code used in previous works. The results of the extensive evaluation on the datasets demonstrate that Devign outperforms the state of the arts significantly with an average of 10.51% higher accuracy and 8.68\% F1 score, increases averagely 4.66% accuracy and 6.37% F1 by the Conv module.
Networked Stochastic Multi-Armed Bandits with Combinatorial Strategies
Mar 20, 2015

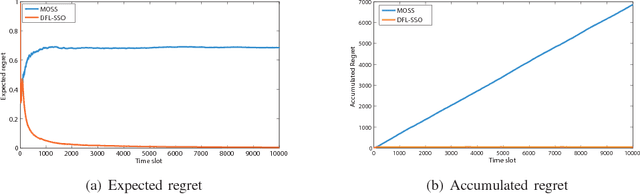

In this paper, we investigate a largely extended version of classical MAB problem, called networked combinatorial bandit problems. In particular, we consider the setting of a decision maker over a networked bandits as follows: each time a combinatorial strategy, e.g., a group of arms, is chosen, and the decision maker receives a reward resulting from her strategy and also receives a side bonus resulting from that strategy for each arm's neighbor. This is motivated by many real applications such as on-line social networks where friends can provide their feedback on shared content, therefore if we promote a product to a user, we can also collect feedback from her friends on that product. To this end, we consider two types of side bonus in this study: side observation and side reward. Upon the number of arms pulled at each time slot, we study two cases: single-play and combinatorial-play. Consequently, this leaves us four scenarios to investigate in the presence of side bonus: Single-play with Side Observation, Combinatorial-play with Side Observation, Single-play with Side Reward, and Combinatorial-play with Side Reward. For each case, we present and analyze a series of \emph{zero regret} polices where the expect of regret over time approaches zero as time goes to infinity. Extensive simulations validate the effectiveness of our results.
Towards Distribution-Free Multi-Armed Bandits with Combinatorial Strategies
Oct 05, 2014
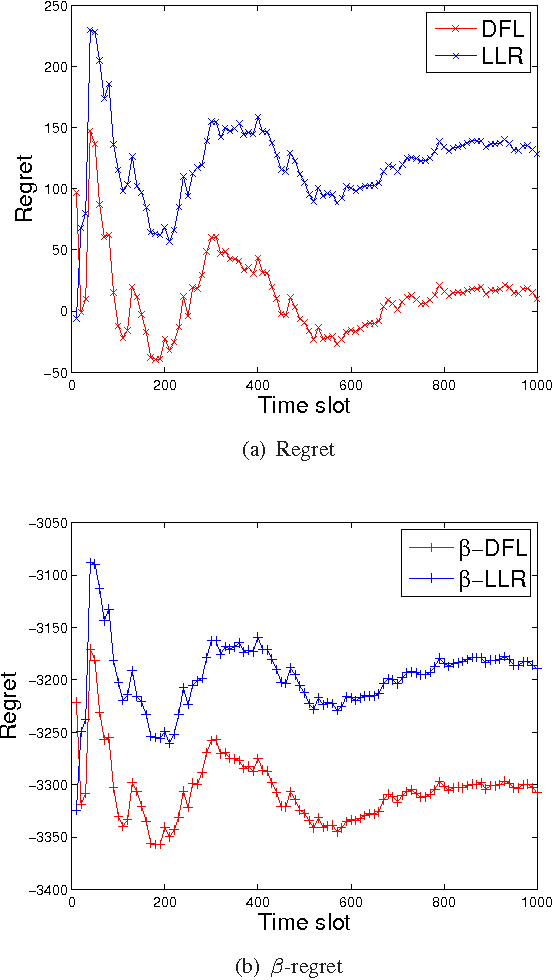

In this paper we study a generalized version of classical multi-armed bandits (MABs) problem by allowing for arbitrary constraints on constituent bandits at each decision point. The motivation of this study comes from many situations that involve repeatedly making choices subject to arbitrary constraints in an uncertain environment: for instance, regularly deciding which advertisements to display online in order to gain high click-through-rate without knowing user preferences, or what route to drive home each day under uncertain weather and traffic conditions. Assume that there are $K$ unknown random variables (RVs), i.e., arms, each evolving as an \emph{i.i.d} stochastic process over time. At each decision epoch, we select a strategy, i.e., a subset of RVs, subject to arbitrary constraints on constituent RVs. We then gain a reward that is a linear combination of observations on selected RVs. The performance of prior results for this problem heavily depends on the distribution of strategies generated by corresponding learning policy. For example, if the reward-difference between the best and second best strategy approaches zero, prior result may lead to arbitrarily large regret. Meanwhile, when there are exponential number of possible strategies at each decision point, naive extension of a prior distribution-free policy would cause poor performance in terms of regret, computation and space complexity. To this end, we propose an efficient Distribution-Free Learning (DFL) policy that achieves zero regret, regardless of the probability distribution of the resultant strategies. Our learning policy has both $O(K)$ time complexity and $O(K)$ space complexity. In successive generations, we show that even if finding the optimal strategy at each decision point is NP-hard, our policy still allows for approximated solutions while retaining near zero-regret.