 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditing Knowledge Representation of Language Lodel via Rephrased Prefix Prompts
Mar 21, 2024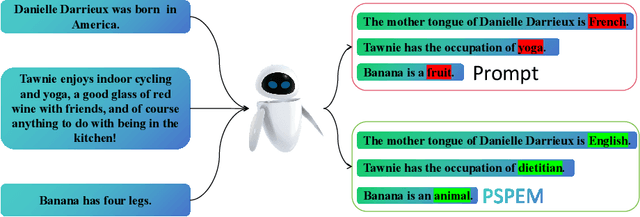



Neural language models (LMs) have been extensively trained on vast corpora to store factual knowledge about various aspects of the world described in texts. Current technologies typically employ knowledge editing methods or specific prompts to modify LM outputs. However, existing knowledge editing methods are costly and inefficient, struggling to produce appropriate text. Additionally, prompt engineering is opaque and requires significant effort to find suitable prompts. To address these issues, we introduce a new method called PSPEM (Prefix Soft Prompt Editing Method), that can be used for a lifetime with just one training. It resolves the inefficiencies and generalizability issues in knowledge editing methods and overcomes the opacity of prompt engineering by automatically seeking optimal soft prompts. Specifically, PSPEM utilizes a prompt encoder and an encoding converter to refine key information in prompts and uses prompt alignment techniques to guide model generation, ensuring text consistency and adherence to the intended structure and content, thereby maintaining an optimal balance between efficiency and accuracy. We have validated the effectiveness of PSPEM through knowledge editing and attribute inserting. On the COUNTERFACT dataset, PSPEM achieved nearly 100\% editing accuracy and demonstrated the highest level of fluency. We further analyzed the similarities between PSPEM and original prompts and their impact on the model's internals. The results indicate that PSPEM can serve as an alternative to original prompts, supporting the model in effective editing.
Locating and Mitigating Gender Bias in Large Language Models
Mar 21, 2024

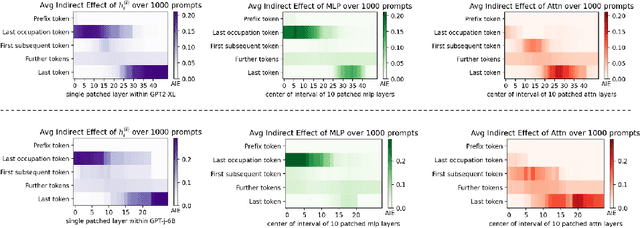

Large language models(LLM) are pre-trained on extensive corpora to learn facts and human cognition which contain human preferences. However, this process can inadvertently lead to these models acquiring biases and stereotypes prevalent in society. Prior research has typically tackled the issue of bias through a one-dimensional perspective, concentrating either on locating or mitigating it. This limited perspective has created obstacles in facilitating research on bias to synergistically complement and progressively build upon one another. In this study, we integrate the processes of locating and mitigating bias within a unified framework. Initially, we use causal mediation analysis to trace the causal effects of different components' activation within a large language model. Building on this, we propose the LSDM (Least Square Debias Method), a knowledge-editing based method for mitigating gender bias in occupational pronouns, and compare it against two baselines on three gender bias datasets and seven knowledge competency test datasets. The experimental results indicate that the primary contributors to gender bias are the bottom MLP modules acting on the last token of occupational pronouns and the top attention module acting on the final word in the sentence. Furthermore, LSDM mitigates gender bias in the model more effectively than the other baselines, while fully preserving the model's capabilities in all other aspects.