 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocating and Mitigating Gender Bias in Large Language Models
Paper and Code


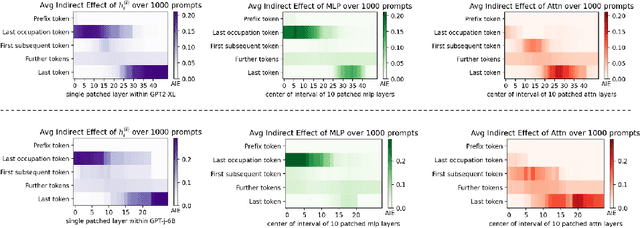

Large language models(LLM) are pre-trained on extensive corpora to learn facts and human cognition which contain human preferences. However, this process can inadvertently lead to these models acquiring biases and stereotypes prevalent in society. Prior research has typically tackled the issue of bias through a one-dimensional perspective, concentrating either on locating or mitigating it. This limited perspective has created obstacles in facilitating research on bias to synergistically complement and progressively build upon one another. In this study, we integrate the processes of locating and mitigating bias within a unified framework. Initially, we use causal mediation analysis to trace the causal effects of different components' activation within a large language model. Building on this, we propose the LSDM (Least Square Debias Method), a knowledge-editing based method for mitigating gender bias in occupational pronouns, and compare it against two baselines on three gender bias datasets and seven knowledge competency test datasets. The experimental results indicate that the primary contributors to gender bias are the bottom MLP modules acting on the last token of occupational pronouns and the top attention module acting on the final word in the sentence. Furthermore, LSDM mitigates gender bias in the model more effectively than the other baselines, while fully preserving the model's capabilities in all other aspects.