 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFMambaNet: Spectral-Frequency Enhanced Selective State Space Model for Correspondence Pruning
Jun 03, 2026Correspondence pruning aims to identify inliers from an initial set of correspondences. Most existing Graph Neural Network (GNN)-based methods rely on geometric features mapped from coarse Euclidean coordinates, which struggle to capture the subtle geometric consistencies presented by inliers. While Mamba-based methods possess global receptive fields and long sequence modeling capabilities, they tend to accumulate substantial inconsistent features within the hidden state space, making it difficult to distinguish inliers from outliers. In this paper, we integrate frequency domain perception into this task for the first time and propose SFMambaNet, a novel Spectral-Frequency enhanced Mamba-based two-view correspondence pruning network. Our method is collaboratively composed of two components: First, we design a Local Spectral-Geometric Attention (LSGA) block. LSGA incorporates spectral positional encoding into local graph interactions and introduces multi-scale Mamba processing to enhance the capture of subtle geometric consistencies and improve local feature discriminability. Building upon this, we design a Spectral-Integrated Global Mamba (SIGM) block. SIGM embeds a frequency gating mechanism within the state space, utilizing the frequency information provided by LSGA to explicitly suppress high-frequency noise accumulation within hidden states and mitigate the propagation of inconsistent features. This enhances inlier-outlier separability and achieves robust global context modeling capabilities with nearly linear complexity. Extensive experiments demonstrate that SFMambaNet outperforms current state-of-the-art methods on several challenging tasks. The code is available at https://github.com/Kirito14IT/SFMambaNet.
GEAR: Granularity-Adaptive Advantage Reweighting for LLM Agents via Self-Distillation
May 14, 2026Reinforcement learning has become a widely used post-training approach for LLM agents, where training commonly relies on outcome-level rewards that provide only coarse supervision. While finer-grained credit assignment is promising for effective policy updates, obtaining reliable local credit and assigning it to the right parts of the long-horizon trajectory remains an open challenge. In this paper, we propose Granularity-adaptivE Advantage Reweighting (GEAR), an adaptive-granularity credit assignment framework that reshapes the trajectory-level GRPO advantage using token- and segment-level signals derived from self-distillation. GEAR compares an on-policy student with a ground-truth-conditioned teacher to obtain a reference-guided divergence signal for identifying adaptive segment boundaries and modulating local advantage weights. This divergence often spikes at the onset of a semantic deviation, while later tokens in the same autoregressive continuation may return to low divergence. GEAR therefore treats such spikes as anchors for adaptive credit regions: where the student remains aligned with the teacher, token-level resolution is preserved; where it departs, GEAR groups the corresponding continuation into an adaptive segment and uses the divergence at the departure point to modulate the segment' s advantage. Experiments across eight mathematical reasoning and agentic tool-use benchmarks with Qwen3 4B and 8B models show that GEAR consistently outperforms standard GRPO, self-distillation-only baselines, and token- or turn-level credit-assignment methods. The gains are especially strong on benchmarks with lower GRPO baseline accuracy, reaching up to around 20\% over GRPO, suggesting that the proposed adaptive reweighting scheme is especially useful in more challenging long-horizon settings.
Token-level Data Selection for Safe LLM Fine-tuning
Mar 01, 2026Fine-tuning large language models (LLMs) on custom datasets has become a standard approach for adapting these models to specific domains and applications. However, recent studies have shown that such fine-tuning can lead to significant degradation in the model's safety. Existing defense methods operate at the sample level and often suffer from an unsatisfactory trade-off between safety and utility. To address this limitation, we perform a systematic token-level diagnosis of safety degradation during fine-tuning. Based on this, we propose token-level data selection for safe LLM fine-tuning (TOSS), a novel framework that quantifies the safety risk of each token by measuring the loss difference between a safety-degraded model and a utility-oriented model. This token-level granularity enables accurate identification and removal of unsafe tokens, thereby preserving valuable task-specific information. In addition, we introduce a progressive refinement strategy, TOSS-Pro, which iteratively enhances the safety-degraded model's ability to identify unsafe tokens. Extensive experiments demonstrate that our approach robustly safeguards LLMs during fine-tuning while achieving superior downstream task performance, significantly outperforming existing sample-level defense methods. Our code is available at https://github.com/Polly-LYP/TOSS.
Learning multi-domain feature relation for visible and Long-wave Infrared image patch matching
Aug 09, 2023Recently, learning-based algorithms have achieved promising performance on cross-spectral image patch matching, which, however, is still far from satisfactory for practical application. On the one hand, a lack of large-scale dataset with diverse scenes haunts its further improvement for learning-based algorithms, whose performances and generalization rely heavily on the dataset size and diversity. On the other hand, more emphasis has been put on feature relation in the spatial domain whereas the scale dependency between features has often been ignored, leading to performance degeneration especially when encountering significant appearance variations for cross-spectral patches. To address these issues, we publish, to be best of our knowledge, the largest visible and Long-wave Infrared (LWIR) image patch matching dataset, termed VL-CMIM, which contains 1300 pairs of strictly aligned visible and LWIR images and over 2 million patch pairs covering diverse scenes such as asteroid, field, country, build, street and water.In addition, a multi-domain feature relation learning network (MD-FRN) is proposed. Input by the features extracted from a four-branch network, both feature relations in spatial and scale domains are learned via a spatial correlation module (SCM) and multi-scale adaptive aggregation module (MSAG), respectively. To further aggregate the multi-domain relations, a deep domain interactive mechanism (DIM) is applied, where the learnt spatial-relation and scale-relation features are exchanged and further input into MSCRM and SCM. This mechanism allows our model to learn interactive cross-domain feature relations, leading to improved robustness to significant appearance changes due to different modality.
Research on Gender-related Fingerprint Features
Aug 18, 2021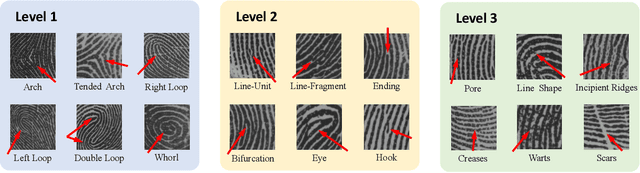
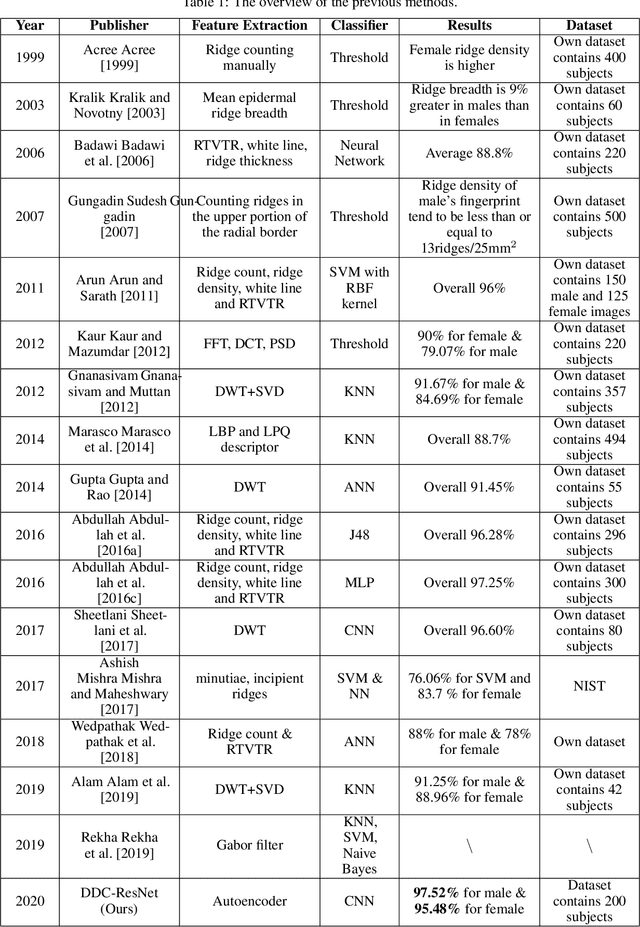
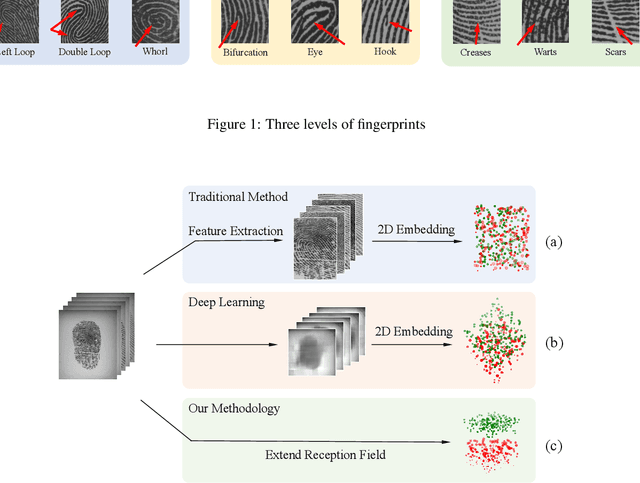
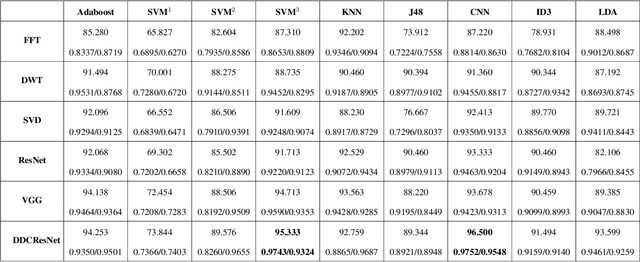
Fingerprint is an important biological feature of human body, which contains abundant gender information. At present, the academic research of fingerprint gender characteristics is generally at the level of understanding, while the standardization research is quite limited. In this work, we propose a more robust method, Dense Dilated Convolution ResNet (DDC-ResNet) to extract valid gender information from fingerprints. By replacing the normal convolution operations with the atrous convolution in the backbone, prior knowledge is provided to keep the edge details and the global reception field can be extended. We explored the results in 3 ways: 1) The efficiency of the DDC-ResNet. 6 typical methods of automatic feature extraction coupling with 9 mainstream classifiers are evaluated in our dataset with fair implementation details. Experimental results demonstrate that the combination of our approach outperforms other combinations in terms of average accuracy and separate-gender accuracy. It reaches 96.5% for average and 0.9752 (males)/0.9548 (females) for separate-gender accuracy. 2) The effect of fingers. It is found that the best performance of classifying gender with separate fingers is achieved by the right ring finger. 3) The effect of specific features. Based on the observations of the concentrations of fingerprints visualized by our approach, it can be inferred that loops and whorls (level 1), bifurcations (level 2), as well as line shapes (level 3) are connected with gender. Finally, we will open source the dataset that contains 6000 fingerprint images