 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Geometric Optimization for Deep Learning: From Euclidean Space to Riemannian Manifold
Feb 16, 2023

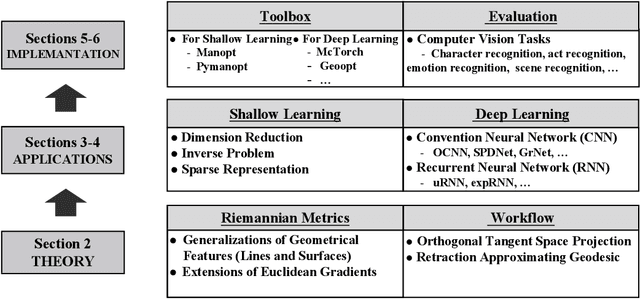

Although Deep Learning (DL) has achieved success in complex Artificial Intelligence (AI) tasks, it suffers from various notorious problems (e.g., feature redundancy, and vanishing or exploding gradients), since updating parameters in Euclidean space cannot fully exploit the geometric structure of the solution space. As a promising alternative solution, Riemannian-based DL uses geometric optimization to update parameters on Riemannian manifolds and can leverage the underlying geometric information. Accordingly, this article presents a comprehensive survey of applying geometric optimization in DL. At first, this article introduces the basic procedure of the geometric optimization, including various geometric optimizers and some concepts of Riemannian manifold. Subsequently, this article investigates the application of geometric optimization in different DL networks in various AI tasks, e.g., convolution neural network, recurrent neural network, transfer learning, and optimal transport. Additionally, typical public toolboxes that implement optimization on manifold are also discussed. Finally, this article makes a performance comparison between different deep geometric optimization methods under image recognition scenarios.
O-ViT: Orthogonal Vision Transformer
Feb 16, 2022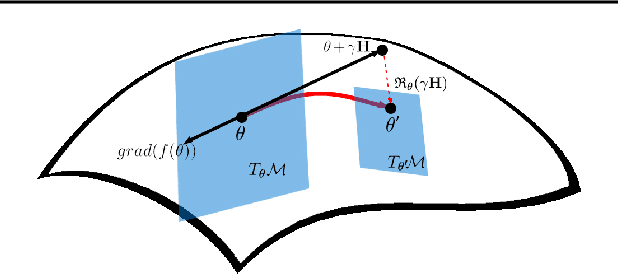
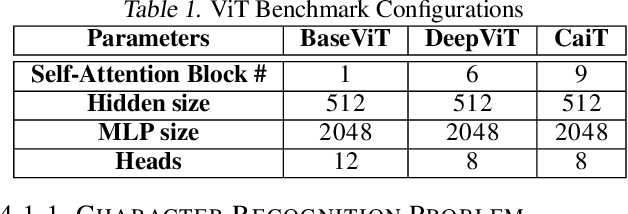
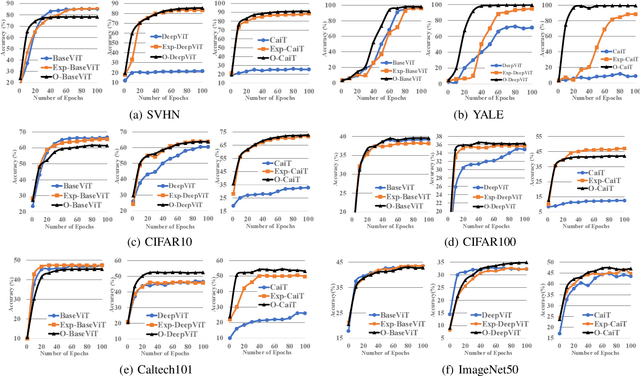
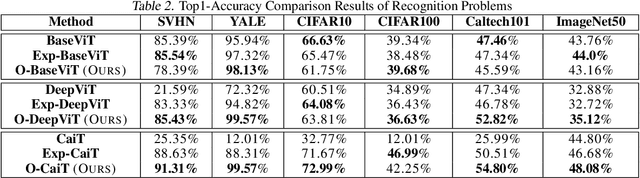
Inspired by the tremendous success of the self-attention mechanism in natural language processing, the Vision Transformer (ViT) creatively applies it to image patch sequences and achieves incredible performance. However, the scaled dot-product self-attention of ViT brings about scale ambiguity to the structure of the original feature space. To address this problem, we propose a novel method named Orthogonal Vision Transformer (O-ViT), to optimize ViT from the geometric perspective. O-ViT limits parameters of self-attention blocks to be on the norm-keeping orthogonal manifold, which can keep the geometry of the feature space. Moreover, O-ViT achieves both orthogonal constraints and cheap optimization overhead by adopting a surjective mapping between the orthogonal group and its Lie algebra.We have conducted comparative experiments on image recognition tasks to demonstrate O-ViT's validity and experiments show that O-ViT can boost the performance of ViT by up to 3.6%.