 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFNAS: Uncertainty-Aware Fast Neural Architecture Search
May 27, 2021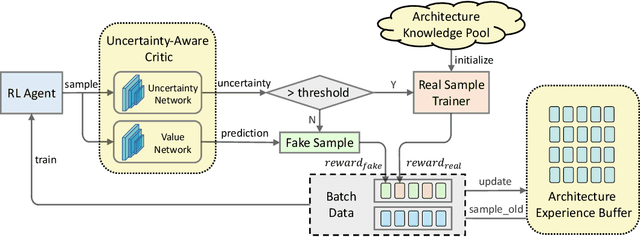
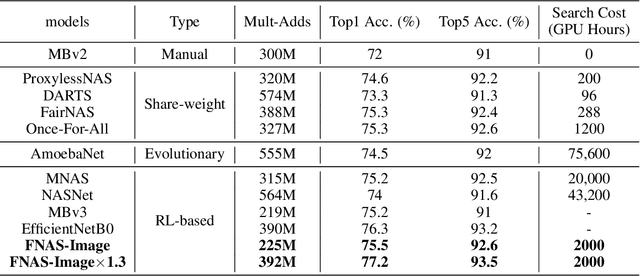
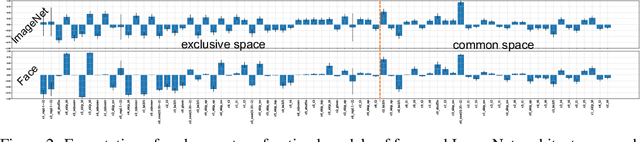
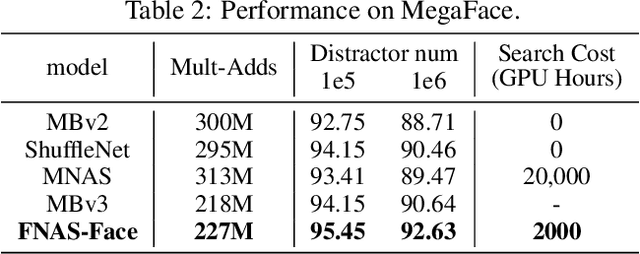
Reinforcement learning (RL)-based neural architecture search (NAS) generally guarantees better convergence yet suffers from the requirement of huge computational resources compared with gradient-based approaches, due to the rollout bottleneck -- exhaustive training for each sampled generation on proxy tasks. In this paper, we propose a general pipeline to accelerate the convergence of the rollout process as well as the RL process in NAS. It is motivated by the interesting observation that both the architecture and the parameter knowledge can be transferred between different experiments and even different tasks. We first introduce an uncertainty-aware critic (value function) in Proximal Policy Optimization (PPO) to utilize the architecture knowledge in previous experiments, which stabilizes the training process and reduces the searching time by 4 times. Further, an architecture knowledge pool together with a block similarity function is proposed to utilize parameter knowledge and reduces the searching time by 2 times. It is the first to introduce block-level weight sharing in RLbased NAS. The block similarity function guarantees a 100% hitting ratio with strict fairness. Besides, we show that a simply designed off-policy correction factor used in "replay buffer" in RL optimization can further reduce half of the searching time. Experiments on the Mobile Neural Architecture Search (MNAS) search space show the proposed Fast Neural Architecture Search (FNAS) accelerates standard RL-based NAS process by ~10x (e.g. ~256 2x2 TPUv2 x days / 20,000 GPU x hour -> 2,000 GPU x hour for MNAS), and guarantees better performance on various vision tasks.