 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Product Flow Matching: Decoupling Radial and Angular Dynamics for Few-Shot Adaptation
May 06, 2026Recent flow matching (FM) methods improve the few-shot adaptation of vision-language models, by modeling cross-modal alignment as a continuous multi-step flow. In this paper, we argue that existing FM methods are inherently constrained by incompatible geometric priors on pre-trained cross-modal features, resulting in suboptimal adaptation performance. We first analyze these methods from a polar decomposition perspective (i.e., radial and angular sub-manifolds). Under this new geometric view, we identify three overlooked limitations in them: 1) Angular dynamics distortion: The radial-angular coupling induces non-uniform speed on the angular sub-manifold, leading to regression training difficulty and extra truncation errors. 2) Radial dynamics neglect: Feature normalization discards modality confidence, failing to distinguish out-of-distribution and in-distribution data, and abandoning crucial radial dynamics. 3) Context-agnostic unconditional flow: Dataset-specific information loss during pre-trained cross-modal feature extraction remains unrecovered. To resolve these issues, we propose warped product flow matching (WP-FM), a unified Riemannian framework that reformulates alignment on a warped product manifold. Within this framework, we derive direct product flow matching (DP-FM) by introducing a constant-warping metric, which yields a decoupled cylindrical manifold (i.e., direct product manifold). DP-FM enables independent radial evolution and constant-speed angular geodesic transport, effectively eliminating angular dynamics distortion while preserving radial consistency. Meanwhile, we incorporate classifier-free guidance by conditioning the flow on the pre-trained VLMs' hidden states to inject missing dataset-specific information. Extensive results across 11 benchmarks have demonstrated that DP-FM achieves a new state-of-the-art for multi-step few-shot adaptation.
Coarse-Guided Visual Generation via Weighted h-Transform Sampling
Mar 12, 2026Coarse-guided visual generation, which synthesizes fine visual samples from degraded or low-fidelity coarse references, is essential for various real-world applications. While training-based approaches are effective, they are inherently limited by high training costs and restricted generalization due to paired data collection. Accordingly, recent training-free works propose to leverage pretrained diffusion models and incorporate guidance during the sampling process. However, these training-free methods either require knowing the forward (fine-to-coarse) transformation operator, e.g., bicubic downsampling, or are difficult to balance between guidance and synthetic quality. To address these challenges, we propose a novel guided method by using the h-transform, a tool that can constrain stochastic processes (e.g., sampling process) under desired conditions. Specifically, we modify the transition probability at each sampling timestep by adding to the original differential equation with a drift function, which approximately steers the generation toward the ideal fine sample. To address unavoidable approximation errors, we introduce a noise-level-aware schedule that gradually de-weights the term as the error increases, ensuring both guidance adherence and high-quality synthesis. Extensive experiments across diverse image and video generation tasks demonstrate the effectiveness and generalization of our method.
FlowDC: Flow-Based Decoupling-Decay for Complex Image Editing
Dec 12, 2025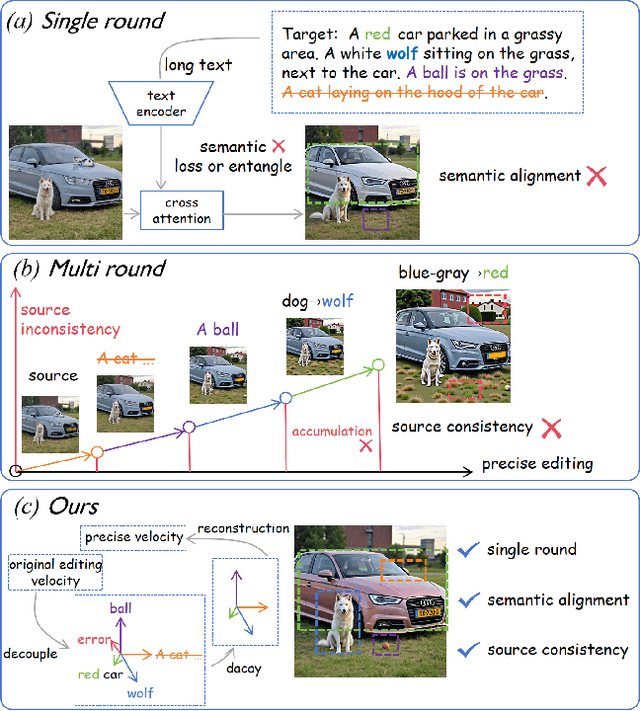
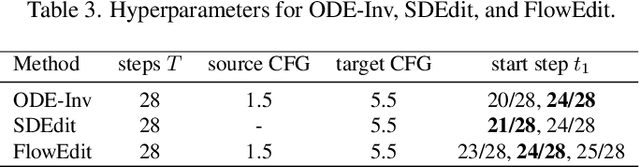

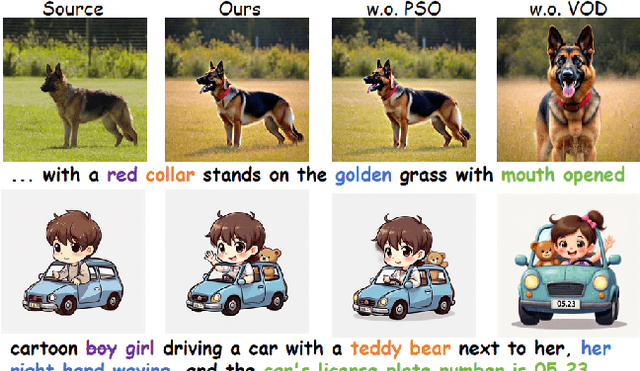
With the surge of pre-trained text-to-image flow matching models, text-based image editing performance has gained remarkable improvement, especially for \underline{simple editing} that only contains a single editing target. To satisfy the exploding editing requirements, the \underline{complex editing} which contains multiple editing targets has posed as a more challenging task. However, current complex editing solutions: single-round and multi-round editing are limited by long text following and cumulative inconsistency, respectively. Thus, they struggle to strike a balance between semantic alignment and source consistency. In this paper, we propose \textbf{FlowDC}, which decouples the complex editing into multiple sub-editing effects and superposes them in parallel during the editing process. Meanwhile, we observed that the velocity quantity that is orthogonal to the editing displacement harms the source structure preserving. Thus, we decompose the velocity and decay the orthogonal part for better source consistency. To evaluate the effectiveness of complex editing settings, we construct a complex editing benchmark: Complex-PIE-Bench. On two benchmarks, FlowDC shows superior results compared with existing methods. We also detail the ablations of our module designs.
Exploring Cross-Modal Flows for Few-Shot Learning
Oct 16, 2025Aligning features from different modalities, is one of the most fundamental challenges for cross-modal tasks. Although pre-trained vision-language models can achieve a general alignment between image and text, they often require parameter-efficient fine-tuning (PEFT) for further adjustment. Today's PEFT methods (e.g., prompt tuning, LoRA-based, or adapter-based) always selectively fine-tune a subset of parameters, which can slightly adjust either visual or textual features, and avoid overfitting. In this paper, we are the first to highlight that all existing PEFT methods perform one-step adjustment. It is insufficient for complex (or difficult) datasets, where features of different modalities are highly entangled. To this end, we propose the first model-agnostic multi-step adjustment approach by learning a cross-modal velocity field: Flow Matching Alignment (FMA). Specifically, to ensure the correspondence between categories during training, we first utilize a fixed coupling strategy. Then, we propose a noise augmentation strategy to alleviate the data scarcity issue. Finally, we design an early-stopping solver, which terminates the transformation process earlier, improving both efficiency and accuracy. Compared with one-step PEFT methods, FMA has the multi-step rectification ability to achieve more precise and robust alignment. Extensive results have demonstrated that FMA can consistently yield significant performance gains across various benchmarks and backbones, particularly on challenging datasets.
Improving Diffusion-based Data Augmentation with Inversion Spherical Interpolation
Aug 29, 2024Data Augmentation (DA), \ie, synthesizing faithful and diverse samples to expand the original training set, is a prevalent and effective strategy to improve various visual recognition tasks. With the powerful image generation ability, diffusion-based DA has shown strong performance gains on different benchmarks. In this paper, we analyze today's diffusion-based DA methods, and argue that they cannot take account of both faithfulness and diversity, which are two critical keys for generating high-quality samples and boosting final classification performance. To this end, we propose a novel Diffusion-based Inversion Interpolation DA method: Diff-II. Specifically, Diff-II consists of three main steps: 1) Category concepts learning: Learning concept embeddings for each category. 2) Inversion interpolation: Calculating the inversion for each image, and conducting spherical interpolation for two randomly sampled inversions from the same category. 3) Two-stage denoising: Using different prompts to generate synthesized images in a coarse-to-fine manner. Extensive experiments on multiple image classification tasks (\eg, few-shot, long-tailed, and out-of-distribution classification) have demonstrated its effectiveness over state-of-the-art diffusion-based DA methods.
Random Boxes Are Open-world Object Detectors
Jul 17, 2023



We show that classifiers trained with random region proposals achieve state-of-the-art Open-world Object Detection (OWOD): they can not only maintain the accuracy of the known objects (w/ training labels), but also considerably improve the recall of unknown ones (w/o training labels). Specifically, we propose RandBox, a Fast R-CNN based architecture trained on random proposals at each training iteration, surpassing existing Faster R-CNN and Transformer based OWOD. Its effectiveness stems from the following two benefits introduced by randomness. First, as the randomization is independent of the distribution of the limited known objects, the random proposals become the instrumental variable that prevents the training from being confounded by the known objects. Second, the unbiased training encourages more proposal explorations by using our proposed matching score that does not penalize the random proposals whose prediction scores do not match the known objects. On two benchmarks: Pascal-VOC/MS-COCO and LVIS, RandBox significantly outperforms the previous state-of-the-art in all metrics. We also detail the ablations on randomization and loss designs. Codes are available at https://github.com/scuwyh2000/RandBox.