 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering ChatGPT-Like Large-Scale Language Models with Local Knowledge Base for Industrial Prognostics and Health Management
Dec 06, 2023Prognostics and health management (PHM) is essential for industrial operation and maintenance, focusing on predicting, diagnosing, and managing the health status of industrial systems. The emergence of the ChatGPT-Like large-scale language model (LLM) has begun to lead a new round of innovation in the AI field. It has extensively promoted the level of intelligence in various fields. Therefore, it is also expected further to change the application paradigm in industrial PHM and promote PHM to become intelligent. Although ChatGPT-Like LLMs have rich knowledge reserves and powerful language understanding and generation capabilities, they lack domain-specific expertise, significantly limiting their practicability in PHM applications. To this end, this study explores the ChatGPT-Like LLM empowered by the local knowledge base (LKB) in industrial PHM to solve the above limitations. In addition, we introduce the method and steps of combining the LKB with LLMs, including LKB preparation, LKB vectorization, prompt engineering, etc. Experimental analysis of real cases shows that combining the LKB with ChatGPT-Like LLM can significantly improve its performance and make ChatGPT-Like LLMs more accurate, relevant, and able to provide more insightful information. This can promote the development of ChatGPT-Like LLMs in industrial PHM and promote their efficiency and quality.
ChatGPT-Like Large-Scale Foundation Models for Prognostics and Health Management: A Survey and Roadmaps
May 12, 2023Prognostics and health management (PHM) technology plays a critical role in industrial production and equipment maintenance by identifying and predicting possible equipment failures and damages, thereby allowing necessary maintenance measures to be taken to enhance equipment service life and reliability while reducing production costs and downtime. In recent years, PHM technology based on artificial intelligence (AI) has made remarkable achievements in the context of the industrial IoT and big data, and it is widely used in various industries, such as railway, energy, and aviation, for condition monitoring, fault prediction, and health management. The emergence of large-scale foundation models (LSF-Models) such as ChatGPT and DALLE-E marks the entry of AI into a new era of AI-2.0 from AI-1.0, where deep models have rapidly evolved from a research paradigm of single-modal, single-task, and limited-data to a multi-modal, multi-task, massive data, and super-large model paradigm. ChatGPT represents a landmark achievement in this research paradigm, offering hope for general artificial intelligence due to its highly intelligent natural language understanding ability. However, the PHM field lacks a consensus on how to respond to this significant change in the AI field, and a systematic review and roadmap is required to elucidate future development directions. To fill this gap, this paper systematically expounds on the key components and latest developments of LSF-Models. Then, we systematically answered how to build the LSF-Model applicable to PHM tasks and outlined the challenges and future development roadmaps for this research paradigm.
Weakly Supervised-Based Oversampling for High Imbalance and High Dimensionality Data Classification
Oct 06, 2020
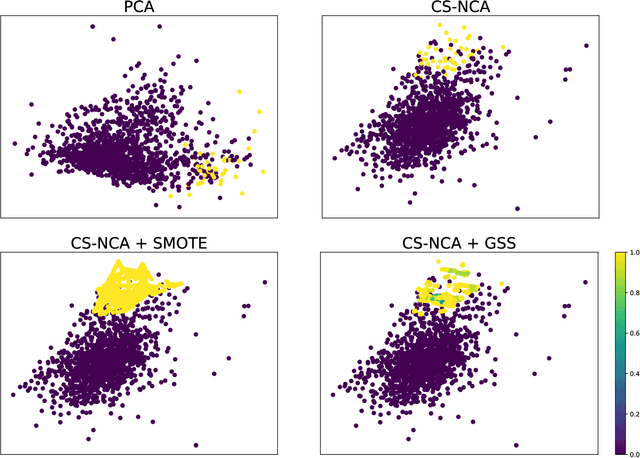

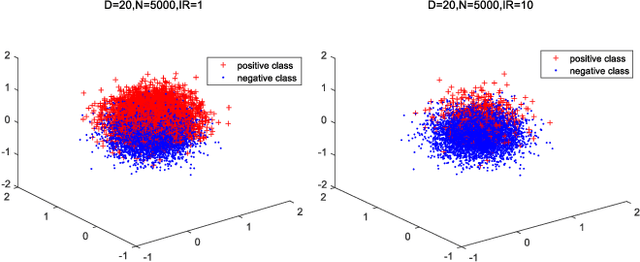
With the abundance of industrial datasets, imbalanced classification has become a common problem in several application domains. Oversampling is an effective method to solve imbalanced classification. One of the main challenges of the existing oversampling methods is to accurately label the new synthetic samples. Inaccurate labels of the synthetic samples would distort the distribution of the dataset and possibly worsen the classification performance. This paper introduces the idea of weakly supervised learning to handle the inaccurate labeling of synthetic samples caused by traditional oversampling methods. Graph semi-supervised SMOTE is developed to improve the credibility of the synthetic samples' labels. In addition, we propose cost-sensitive neighborhood components analysis for high dimensional datasets and bootstrap based ensemble framework for highly imbalanced datasets. The proposed method has achieved good classification performance on 8 synthetic datasets and 3 real-world datasets, especially for high imbalance and high dimensionality problems. The average performances and robustness are better than the benchmark methods.