 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised-Based Oversampling for High Imbalance and High Dimensionality Data Classification
Paper and Code
Oct 06, 2020
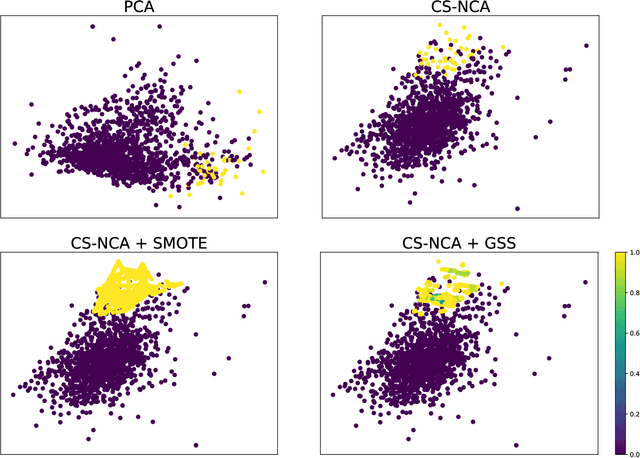

With the abundance of industrial datasets, imbalanced classification has become a common problem in several application domains. Oversampling is an effective method to solve imbalanced classification. One of the main challenges of the existing oversampling methods is to accurately label the new synthetic samples. Inaccurate labels of the synthetic samples would distort the distribution of the dataset and possibly worsen the classification performance. This paper introduces the idea of weakly supervised learning to handle the inaccurate labeling of synthetic samples caused by traditional oversampling methods. Graph semi-supervised SMOTE is developed to improve the credibility of the synthetic samples' labels. In addition, we propose cost-sensitive neighborhood components analysis for high dimensional datasets and bootstrap based ensemble framework for highly imbalanced datasets. The proposed method has achieved good classification performance on 8 synthetic datasets and 3 real-world datasets, especially for high imbalance and high dimensionality problems. The average performances and robustness are better than the benchmark methods.