 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-CI: Assessing Contextual Integrity Norms in Language Models
Sep 05, 2024



Large language models (LLMs), while memorizing parts of their training data scraped from the Internet, may also inadvertently encode societal preferences and norms. As these models are integrated into sociotechnical systems, it is crucial that the norms they encode align with societal expectations. These norms could vary across models, hyperparameters, optimization techniques, and datasets. This is especially challenging due to prompt sensitivity$-$small variations in prompts yield different responses, rendering existing assessment methodologies unreliable. There is a need for a comprehensive framework covering various models, optimization, and datasets, along with a reliable methodology to assess encoded norms. We present LLM-CI, the first open-sourced framework to assess privacy norms encoded in LLMs. LLM-CI uses a Contextual Integrity-based factorial vignette methodology to assess the encoded norms across different contexts and LLMs. We propose the multi-prompt assessment methodology to address prompt sensitivity by assessing the norms from only the prompts that yield consistent responses across multiple variants. Using LLM-CI and our proposed methodology, we comprehensively evaluate LLMs using IoT and COPPA vignettes datasets from prior work, examining the impact of model properties (e.g., hyperparameters, capacity) and optimization strategies (e.g., alignment, quantization).
Beyond The Text: Analysis of Privacy Statements through Syntactic and Semantic Role Labeling
Oct 01, 2020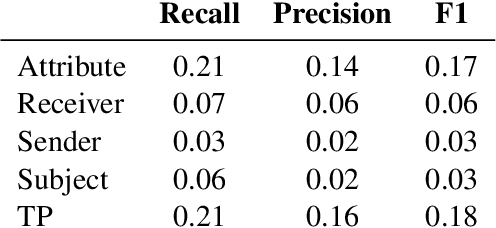
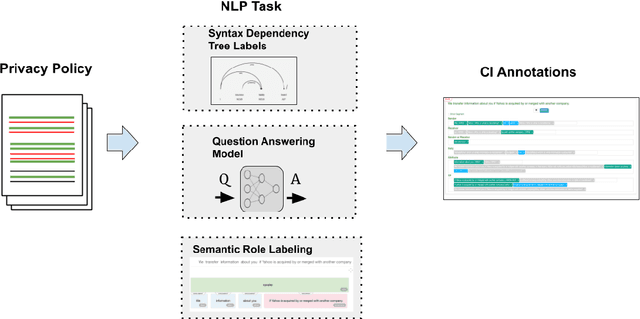
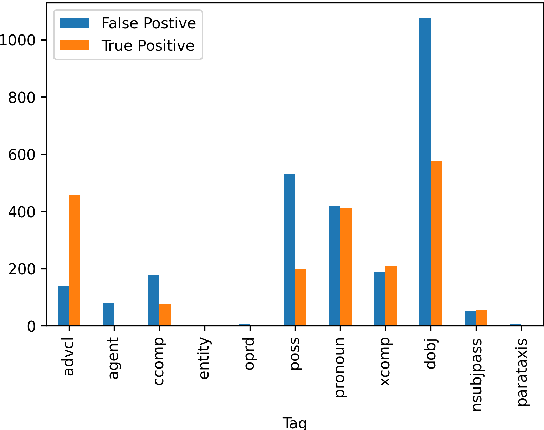

This paper formulates a new task of extracting privacy parameters from a privacy policy, through the lens of Contextual Integrity, an established social theory framework for reasoning about privacy norms. Privacy policies, written by lawyers, are lengthy and often comprise incomplete and vague statements. In this paper, we show that traditional NLP tasks, including the recently proposed Question-Answering based solutions, are insufficient to address the privacy parameter extraction problem and provide poor precision and recall. We describe 4 different types of conventional methods that can be partially adapted to address the parameter extraction task with varying degrees of success: Hidden Markov Models, BERT fine-tuned models, Dependency Type Parsing (DP) and Semantic Role Labeling (SRL). Based on a detailed evaluation across 36 real-world privacy policies of major enterprises, we demonstrate that a solution combining syntactic DP coupled with type-specific SRL tasks provides the highest accuracy for retrieving contextual privacy parameters from privacy statements. We also observe that incorporating domain-specific knowledge is critical to achieving high precision and recall, thus inspiring new NLP research to address this important problem in the privacy domain.