 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond The Text: Analysis of Privacy Statements through Syntactic and Semantic Role Labeling
Oct 01, 2020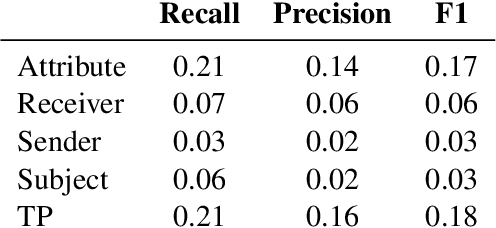
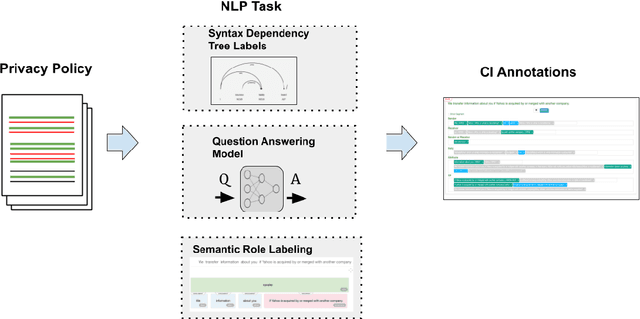
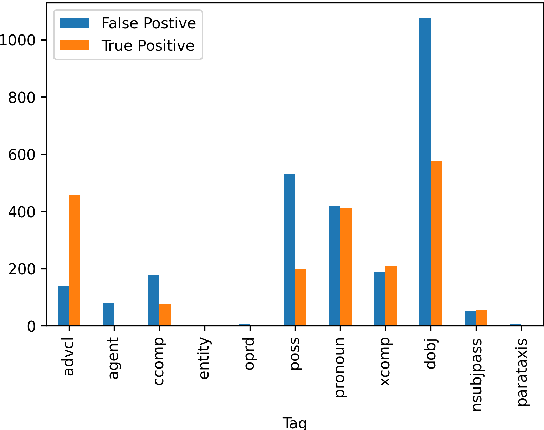

This paper formulates a new task of extracting privacy parameters from a privacy policy, through the lens of Contextual Integrity, an established social theory framework for reasoning about privacy norms. Privacy policies, written by lawyers, are lengthy and often comprise incomplete and vague statements. In this paper, we show that traditional NLP tasks, including the recently proposed Question-Answering based solutions, are insufficient to address the privacy parameter extraction problem and provide poor precision and recall. We describe 4 different types of conventional methods that can be partially adapted to address the parameter extraction task with varying degrees of success: Hidden Markov Models, BERT fine-tuned models, Dependency Type Parsing (DP) and Semantic Role Labeling (SRL). Based on a detailed evaluation across 36 real-world privacy policies of major enterprises, we demonstrate that a solution combining syntactic DP coupled with type-specific SRL tasks provides the highest accuracy for retrieving contextual privacy parameters from privacy statements. We also observe that incorporating domain-specific knowledge is critical to achieving high precision and recall, thus inspiring new NLP research to address this important problem in the privacy domain.