 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic ICD-10 Code Association: A Challenging Task on French Clinical Texts
Apr 06, 2023



Automatically associating ICD codes with electronic health data is a well-known NLP task in medical research. NLP has evolved significantly in recent years with the emergence of pre-trained language models based on Transformers architecture, mainly in the English language. This paper adapts these models to automatically associate the ICD codes. Several neural network architectures have been experimented with to address the challenges of dealing with a large set of both input tokens and labels to be guessed. In this paper, we propose a model that combines the latest advances in NLP and multi-label classification for ICD-10 code association. Fair experiments on a Clinical dataset in the French language show that our approach increases the $F_1$-score metric by more than 55\% compared to state-of-the-art results.
An Easy-to-use and Robust Approach for the Differentially Private De-Identification of Clinical Textual Documents
Nov 02, 2022Unstructured textual data is at the heart of healthcare systems. For obvious privacy reasons, these documents are not accessible to researchers as long as they contain personally identifiable information. One way to share this data while respecting the legislative framework (notably GDPR or HIPAA) is, within the medical structures, to de-identify it, i.e. to detect the personal information of a person through a Named Entity Recognition (NER) system and then replacing it to make it very difficult to associate the document with the person. The challenge is having reliable NER and substitution tools without compromising confidentiality and consistency in the document. Most of the conducted research focuses on English medical documents with coarse substitutions by not benefiting from advances in privacy. This paper shows how an efficient and differentially private de-identification approach can be achieved by strengthening the less robust de-identification method and by adapting state-of-the-art differentially private mechanisms for substitution purposes. The result is an approach for de-identifying clinical documents in French language, but also generalizable to other languages and whose robustness is mathematically proven.
De-Identification of French Unstructured Clinical Notes for Machine Learning Tasks
Sep 16, 2022
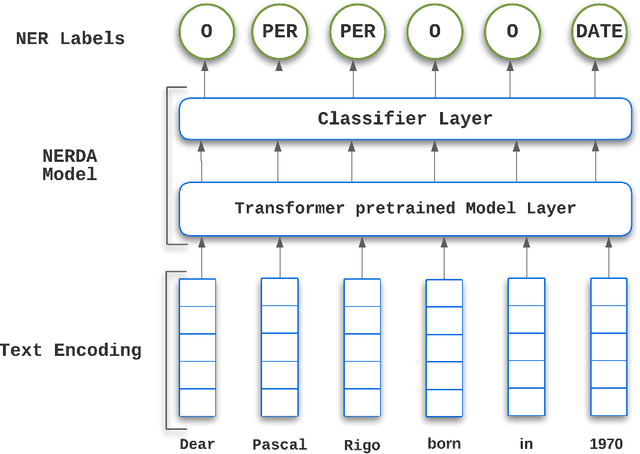
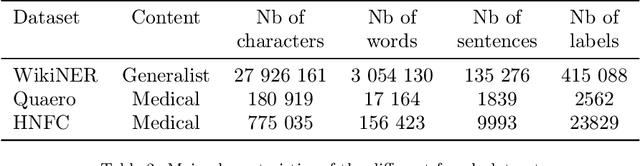
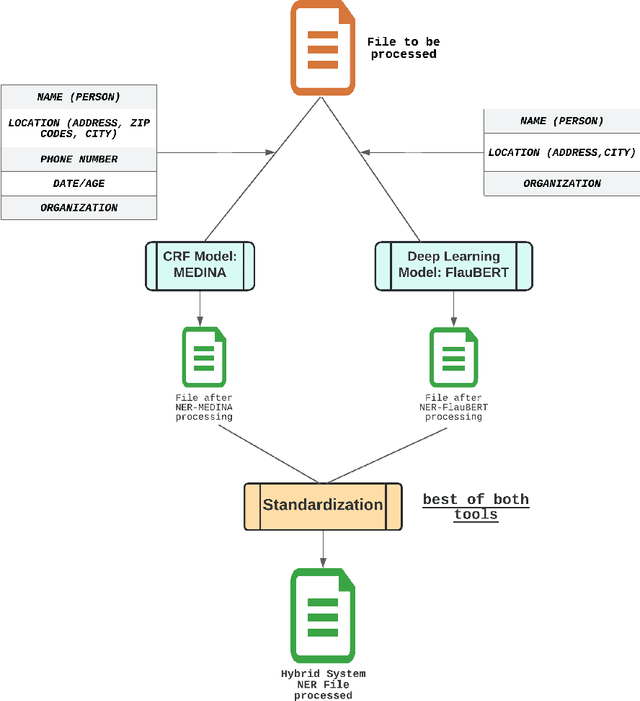
Unstructured textual data are at the heart of health systems: liaison letters between doctors, operating reports, coding of procedures according to the ICD-10 standard, etc. The details included in these documents make it possible to get to know the patient better, to better manage him or her, to better study the pathologies, to accurately remunerate the associated medical acts\ldots All this seems to be (at least partially) within reach of today by artificial intelligence techniques. However, for obvious reasons of privacy protection, the designers of these AIs do not have the legal right to access these documents as long as they contain identifying data. De-identifying these documents, i.e. detecting and deleting all identifying information present in them, is a legally necessary step for sharing this data between two complementary worlds. Over the last decade, several proposals have been made to de-identify documents, mainly in English. While the detection scores are often high, the substitution methods are often not very robust to attack. In French, very few methods are based on arbitrary detection and/or substitution rules. In this paper, we propose a new comprehensive de-identification method dedicated to French-language medical documents. Both the approach for the detection of identifying elements (based on deep learning) and their substitution (based on differential privacy) are based on the most proven existing approaches. The result is an approach that effectively protects the privacy of the patients at the heart of these medical documents. The whole approach has been evaluated on a French language medical dataset of a French public hospital and the results are very encouraging.