 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-Identification of French Unstructured Clinical Notes for Machine Learning Tasks
Paper and Code
Sep 16, 2022
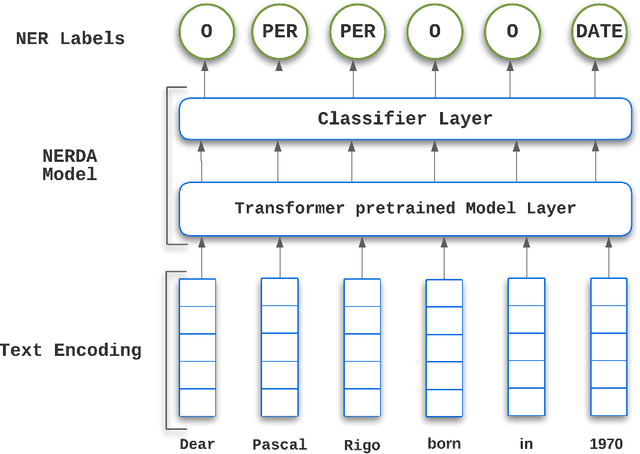
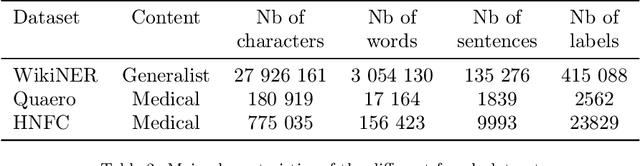
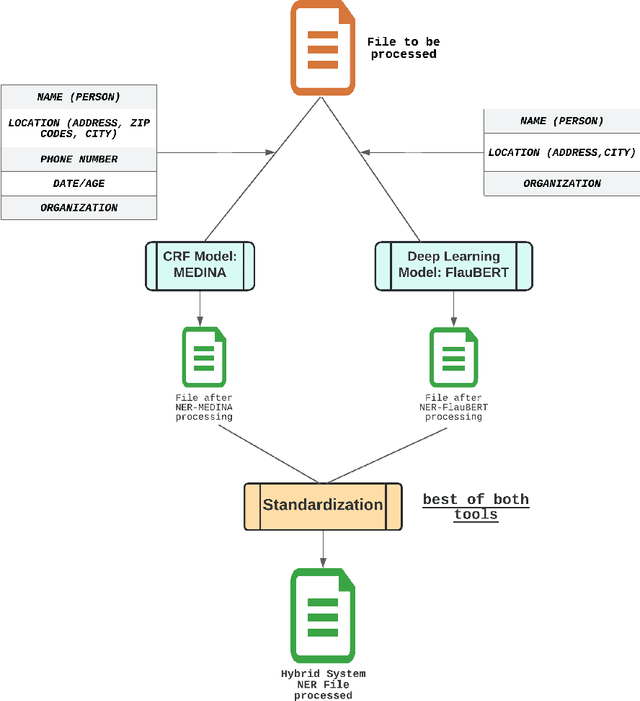
Unstructured textual data are at the heart of health systems: liaison letters between doctors, operating reports, coding of procedures according to the ICD-10 standard, etc. The details included in these documents make it possible to get to know the patient better, to better manage him or her, to better study the pathologies, to accurately remunerate the associated medical acts\ldots All this seems to be (at least partially) within reach of today by artificial intelligence techniques. However, for obvious reasons of privacy protection, the designers of these AIs do not have the legal right to access these documents as long as they contain identifying data. De-identifying these documents, i.e. detecting and deleting all identifying information present in them, is a legally necessary step for sharing this data between two complementary worlds. Over the last decade, several proposals have been made to de-identify documents, mainly in English. While the detection scores are often high, the substitution methods are often not very robust to attack. In French, very few methods are based on arbitrary detection and/or substitution rules. In this paper, we propose a new comprehensive de-identification method dedicated to French-language medical documents. Both the approach for the detection of identifying elements (based on deep learning) and their substitution (based on differential privacy) are based on the most proven existing approaches. The result is an approach that effectively protects the privacy of the patients at the heart of these medical documents. The whole approach has been evaluated on a French language medical dataset of a French public hospital and the results are very encouraging.