 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForensic Dental Age Estimation Using Modified Deep Learning Neural Network
Aug 21, 2022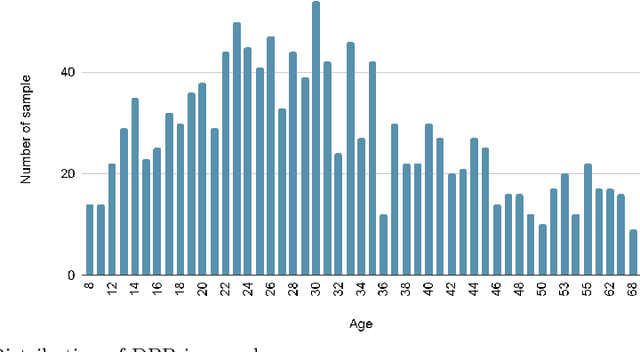
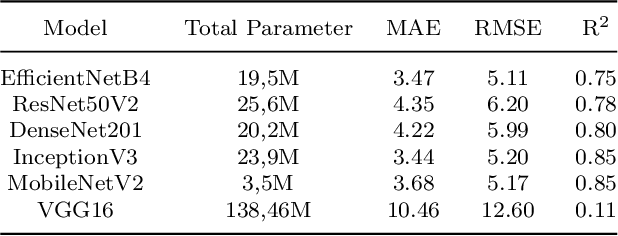

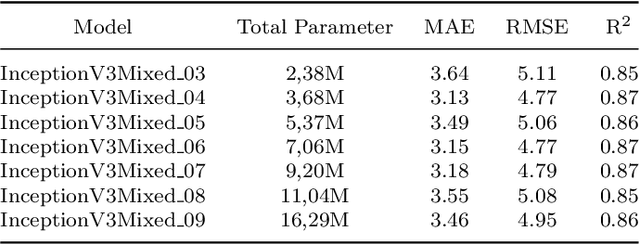
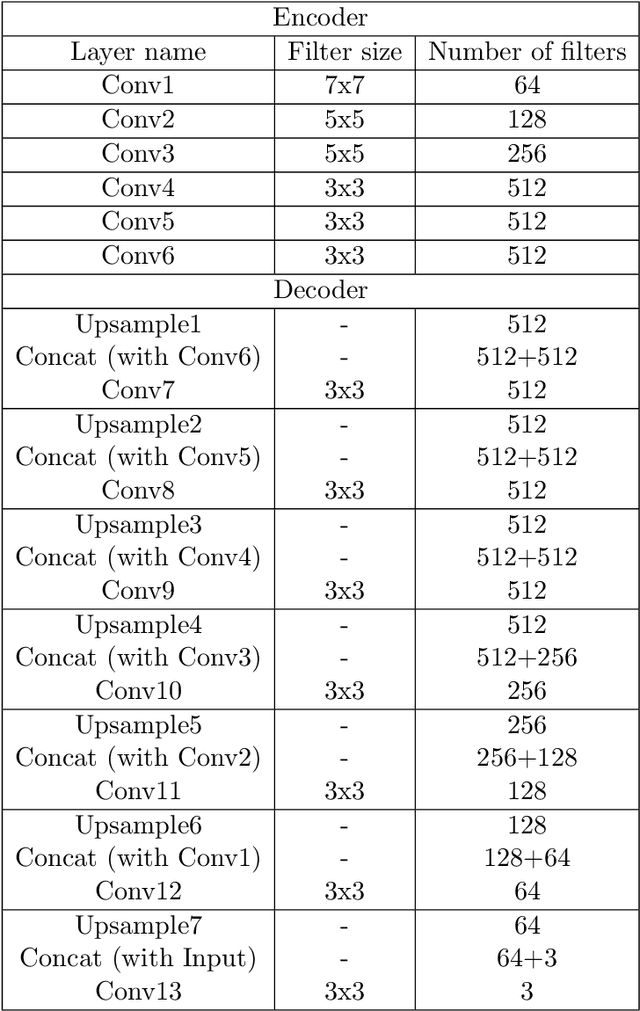
Dental age is one of the most reliable methods to identify an individual's age. By using dental panoramic radiography (DPR) images, physicians and pathologists in forensic sciences try to establish the chronological age of individuals with no valid legal records or registered patients. The current methods in practice demand intensive labor, time, and qualified experts. The development of deep learning algorithms in the field of medical image processing has improved the sensitivity of predicting truth values while reducing the processing speed of imaging time. This study proposed an automated approach to estimate the forensic ages of individuals ranging in age from 8 to 68 using 1,332 DPR images. Initially, experimental analyses were performed with the transfer learning-based models, including InceptionV3, DenseNet201, EfficientNetB4, MobileNetV2, VGG16, and ResNet50V2; and accordingly, the best-performing model, InceptionV3, was modified, and a new neural network model was developed. Reducing the number of the parameters already available in the developed model architecture resulted in a faster and more accurate dental age estimation. The performance metrics of the results attained were as follows: mean absolute error (MAE) was 3.13, root mean square error (RMSE) was 4.77, and correlation coefficient R$^2$ was 87%. It is conceivable to propose the new model as potentially dependable and practical ancillary equipment in forensic sciences and dental medicine.
Iterative Facial Image Inpainting using Cyclic Reverse Generator
Jan 18, 2021
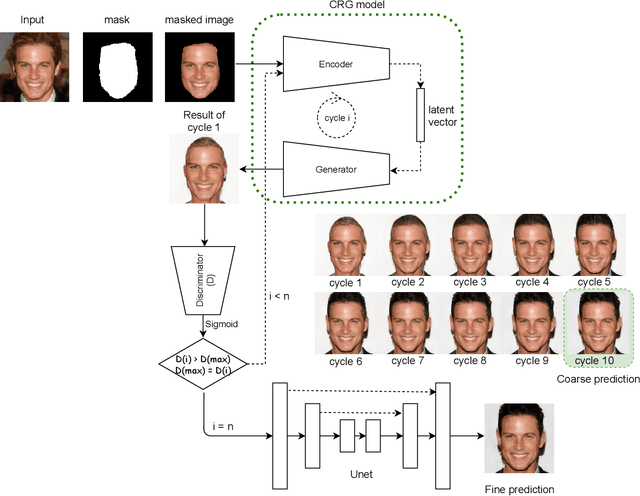

Facial image inpainting is a challenging problem as it requires generating new pixels that include semantic information for masked key components in a face, e.g., eyes and nose. Recently, remarkable methods have been proposed in this field. Most of these approaches use encoder-decoder architectures and have different limitations such as allowing unique results for a given image and a particular mask. Alternatively, some approaches generate promising results using different masks with generator networks. However, these approaches are optimization-based and usually require quite a number of iterations. In this paper, we propose an efficient solution to the facial image painting problem using the Cyclic Reverse Generator (CRG) architecture, which provides an encoder-generator model. We use the encoder to embed a given image to the generator space and incrementally inpaint the masked regions until a plausible image is generated; a discriminator network is utilized to assess the generated images during the iterations. We empirically observed that only a few iterations are sufficient to generate realistic images with the proposed model. After the generation process, for the post processing, we utilize a Unet model that we trained specifically for this task to remedy the artifacts close to the mask boundaries. Our method allows applying sketch-based inpaintings, using variety of mask types, and producing multiple and diverse results. We qualitatively compared our method with the state-of-the-art models and observed that our method can compete with the other models in all mask types; it is particularly better in images where larger masks are utilized.
Semi-supervised Image Attribute Editing using Generative Adversarial Networks
Jul 03, 2019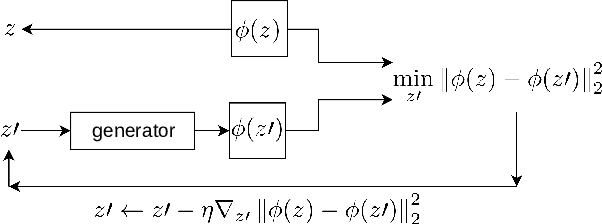
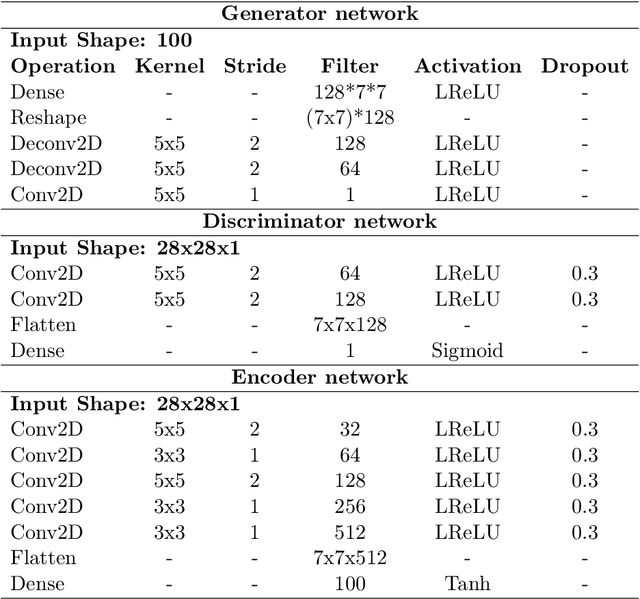
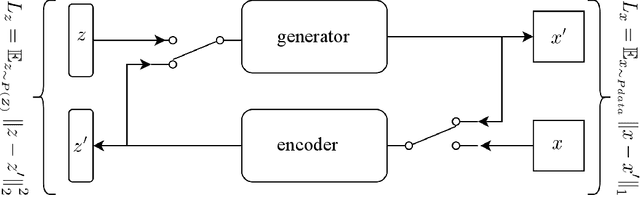

Image attribute editing is a challenging problem that has been recently studied by many researchers using generative networks. The challenge is in the manipulation of selected attributes of images while preserving the other details. The method to achieve this goal is to find an accurate latent vector representation of an image and a direction corresponding to the attribute. Almost all the works in the literature use labeled datasets in a supervised setting for this purpose. In this study, we introduce an architecture called Cyclic Reverse Generator (CRG), which allows learning the inverse function of the generator accurately via an encoder in an unsupervised setting by utilizing cyclic cost minimization. Attribute editing is then performed using the CRG models for finding desired attribute representations in the latent space. In this work, we use two arbitrary reference images, with and without desired attributes, to compute an attribute direction for editing. We show that the proposed approach performs better in terms of image reconstruction compared to the existing end-to-end generative models both quantitatively and qualitatively. We demonstrate state-of-the-art results on both real images and generated images in MNIST and CelebA datasets.