 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Facial Image Inpainting using Cyclic Reverse Generator
Paper and Code

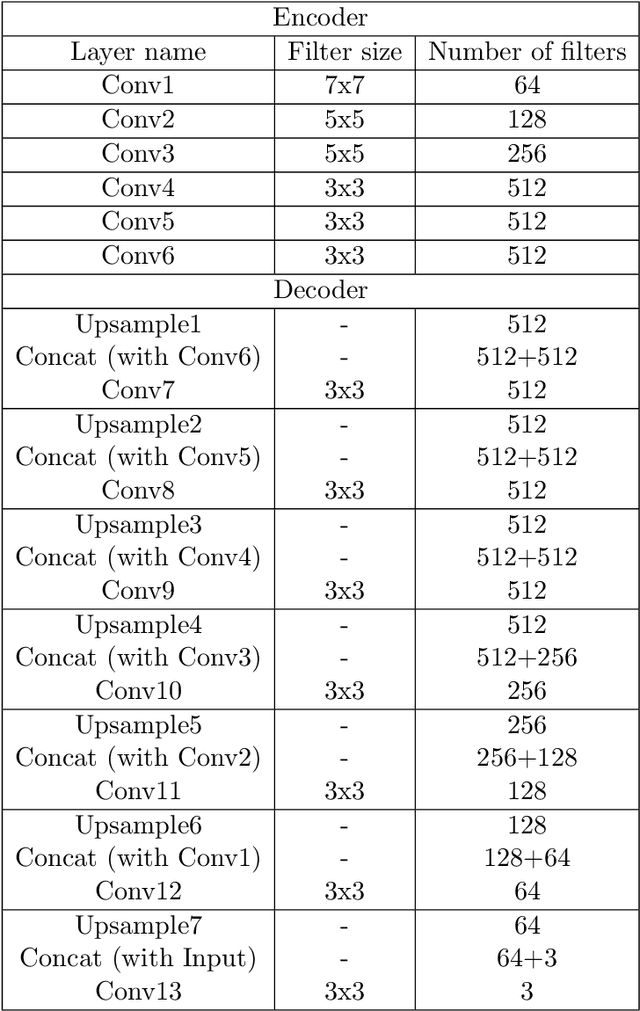
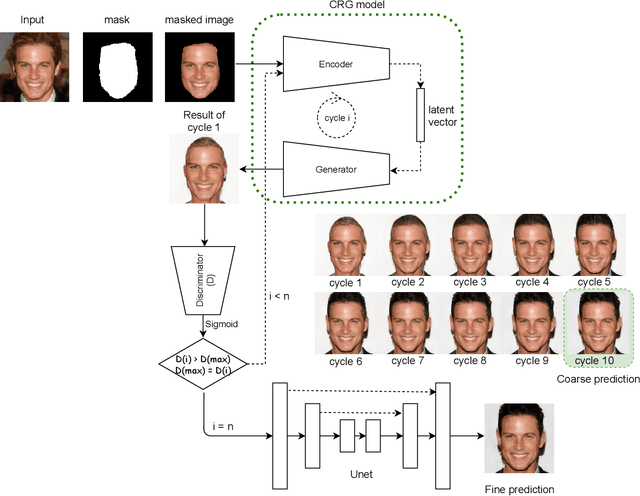

Facial image inpainting is a challenging problem as it requires generating new pixels that include semantic information for masked key components in a face, e.g., eyes and nose. Recently, remarkable methods have been proposed in this field. Most of these approaches use encoder-decoder architectures and have different limitations such as allowing unique results for a given image and a particular mask. Alternatively, some approaches generate promising results using different masks with generator networks. However, these approaches are optimization-based and usually require quite a number of iterations. In this paper, we propose an efficient solution to the facial image painting problem using the Cyclic Reverse Generator (CRG) architecture, which provides an encoder-generator model. We use the encoder to embed a given image to the generator space and incrementally inpaint the masked regions until a plausible image is generated; a discriminator network is utilized to assess the generated images during the iterations. We empirically observed that only a few iterations are sufficient to generate realistic images with the proposed model. After the generation process, for the post processing, we utilize a Unet model that we trained specifically for this task to remedy the artifacts close to the mask boundaries. Our method allows applying sketch-based inpaintings, using variety of mask types, and producing multiple and diverse results. We qualitatively compared our method with the state-of-the-art models and observed that our method can compete with the other models in all mask types; it is particularly better in images where larger masks are utilized.