 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Session Recommendation Systems with Combinatorial Items
Jul 05, 2016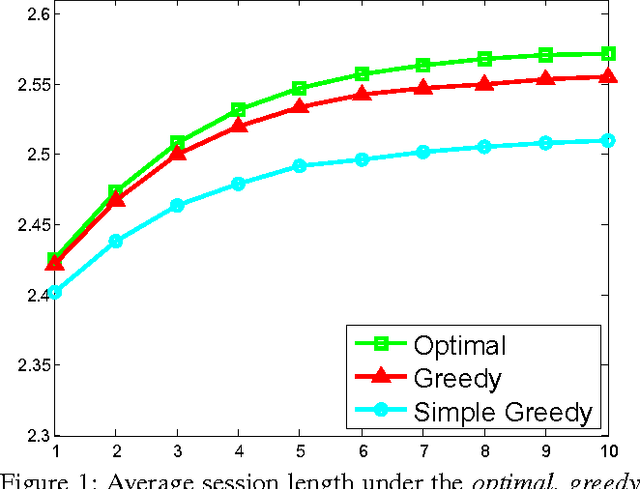
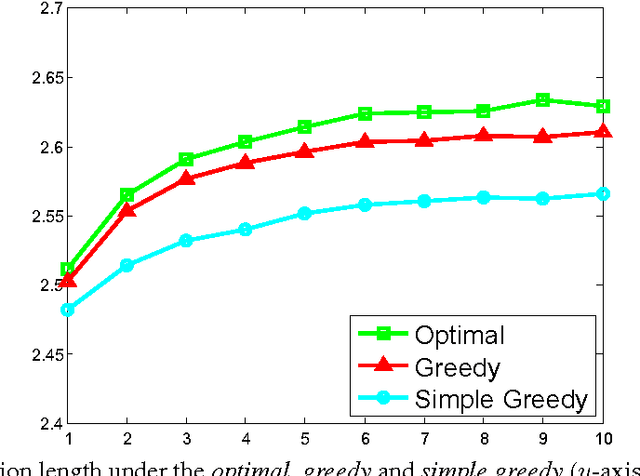
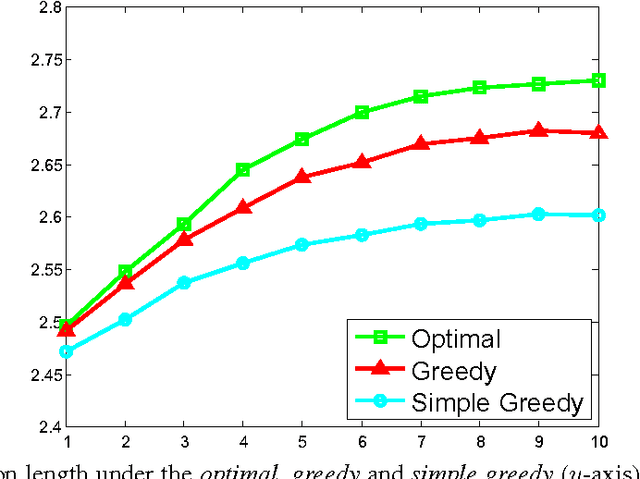
In recent years, content recommendation systems in large websites (or \emph{content providers}) capture an increased focus. While the type of content varies, e.g.\ movies, articles, music, advertisements, etc., the high level problem remains the same. Based on knowledge obtained so far on the user, recommend the most desired content. In this paper we present a method to handle the well known user-cold-start problem in recommendation systems. In this scenario, a recommendation system encounters a new user and the objective is to present items as relevant as possible with the hope of keeping the user's session as long as possible. We formulate an optimization problem aimed to maximize the length of this initial session, as this is believed to be the key to have the user come back and perhaps register to the system. In particular, our model captures the fact that a single round with low quality recommendation is likely to terminate the session. In such a case, we do not proceed to the next round as the user leaves the system, possibly never to seen again. We denote this phenomenon a \emph{One-Shot Session}. Our optimization problem is formulated as an MDP where the action space is of a combinatorial nature as we recommend in each round, multiple items. This huge action space presents a computational challenge making the straightforward solution intractable. We analyze the structure of the MDP to prove monotone and submodular like properties that allow a computationally efficient solution via a method denoted by \emph{Greedy Value Iteration} (G-VI).
The Max $K$-Armed Bandit: PAC Lower Bounds and Efficient Algorithms
Dec 23, 2015We consider the Max $K$-Armed Bandit problem, where a learning agent is faced with several stochastic arms, each a source of i.i.d. rewards of unknown distribution. At each time step the agent chooses an arm, and observes the reward of the obtained sample. Each sample is considered here as a separate item with the reward designating its value, and the goal is to find an item with the highest possible value. Our basic assumption is a known lower bound on the {\em tail function} of the reward distributions. Under the PAC framework, we provide a lower bound on the sample complexity of any $(\epsilon,\delta)$-correct algorithm, and propose an algorithm that attains this bound up to logarithmic factors. We analyze the robustness of the proposed algorithm and in addition, we compare the performance of this algorithm to the variant in which the arms are not distinguishable by the agent and are chosen randomly at each stage. Interestingly, when the maximal rewards of the arms happen to be similar, the latter approach may provide better performance.
The Max $K$-Armed Bandit: A PAC Lower Bound and tighter Algorithms
Aug 23, 2015We consider the Max $K$-Armed Bandit problem, where a learning agent is faced with several sources (arms) of items (rewards), and interested in finding the best item overall. At each time step the agent chooses an arm, and obtains a random real valued reward. The rewards of each arm are assumed to be i.i.d., with an unknown probability distribution that generally differs among the arms. Under the PAC framework, we provide lower bounds on the sample complexity of any $(\epsilon,\delta)$-correct algorithm, and propose algorithms that attain this bound up to logarithmic factors. We compare the performance of this multi-arm algorithms to the variant in which the arms are not distinguishable by the agent and are chosen randomly at each stage. Interestingly, when the maximal rewards of the arms happen to be similar, the latter approach may provide better performance.