 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Policy Optimization with Approximatively Synchronous Advantage Estimation
Dec 07, 2020

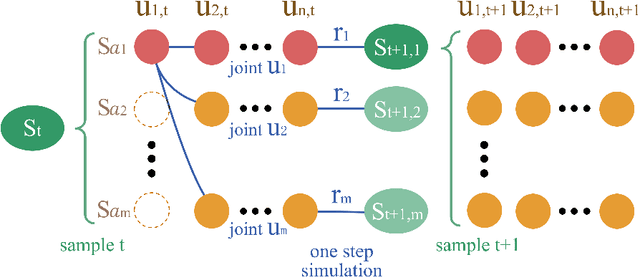

Cooperative multi-agent tasks require agents to deduce their own contributions with shared global rewards, known as the challenge of credit assignment. General methods for policy based multi-agent reinforcement learning to solve the challenge introduce differentiate value functions or advantage functions for individual agents. In multi-agent system, polices of different agents need to be evaluated jointly. In order to update polices synchronously, such value functions or advantage functions also need synchronous evaluation. However, in current methods, value functions or advantage functions use counter-factual joint actions which are evaluated asynchronously, thus suffer from natural estimation bias. In this work, we propose the approximatively synchronous advantage estimation. We first derive the marginal advantage function, an expansion from single-agent advantage function to multi-agent system. Further more, we introduce a policy approximation for synchronous advantage estimation, and break down the multi-agent policy optimization problem into multiple sub-problems of single-agent policy optimization. Our method is compared with baseline algorithms on StarCraft multi-agent challenges, and shows the best performance on most of the tasks.