 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Price Supply Chain Contracts against a Learning Retailer
Nov 02, 2022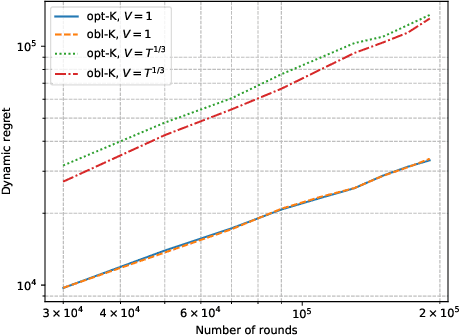
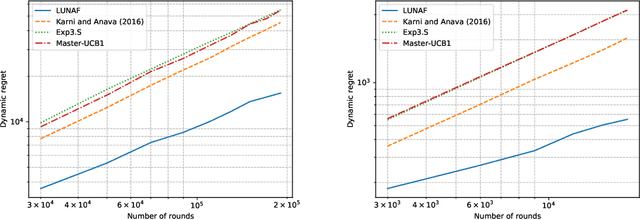
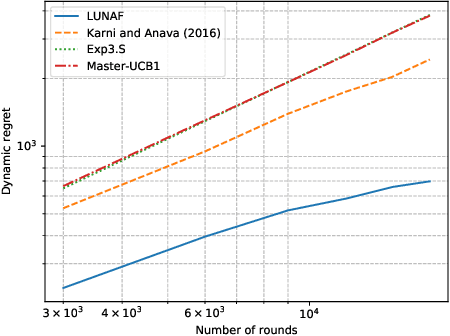
The rise of big data analytics has automated the decision-making of companies and increased supply chain agility. In this paper, we study the supply chain contract design problem faced by a data-driven supplier who needs to respond to the inventory decisions of the downstream retailer. Both the supplier and the retailer are uncertain about the market demand and need to learn about it sequentially. The goal for the supplier is to develop data-driven pricing policies with sublinear regret bounds under a wide range of possible retailer inventory policies for a fixed time horizon. To capture the dynamics induced by the retailer's learning policy, we first make a connection to non-stationary online learning by following the notion of variation budget. The variation budget quantifies the impact of the retailer's learning strategy on the supplier's decision-making. We then propose dynamic pricing policies for the supplier for both discrete and continuous demand. We also note that our proposed pricing policy only requires access to the support of the demand distribution, but critically, does not require the supplier to have any prior knowledge about the retailer's learning policy or the demand realizations. We examine several well-known data-driven policies for the retailer, including sample average approximation, distributionally robust optimization, and parametric approaches, and show that our pricing policies lead to sublinear regret bounds in all these cases. At the managerial level, we answer affirmatively that there is a pricing policy with a sublinear regret bound under a wide range of retailer's learning policies, even though she faces a learning retailer and an unknown demand distribution. Our work also provides a novel perspective in data-driven operations management where the principal has to learn to react to the learning policies employed by other agents in the system.
Exploiting Explanations for Model Inversion Attacks
Apr 26, 2021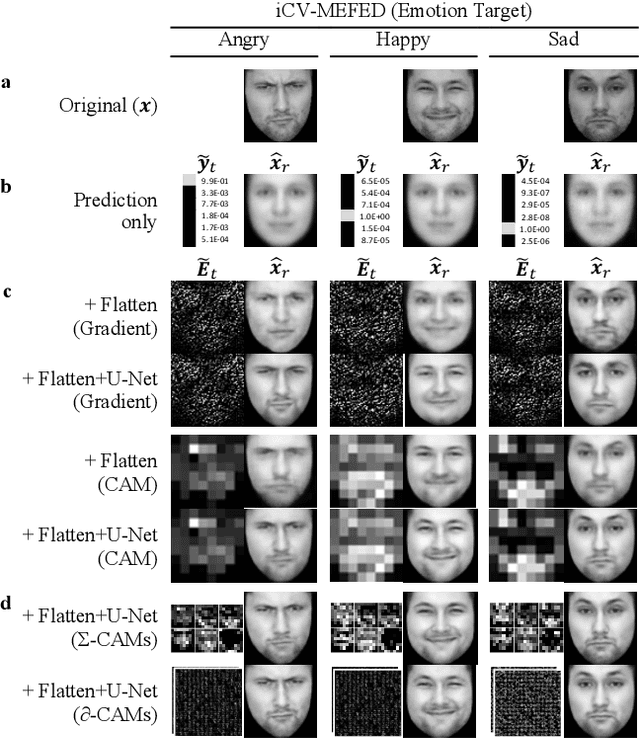
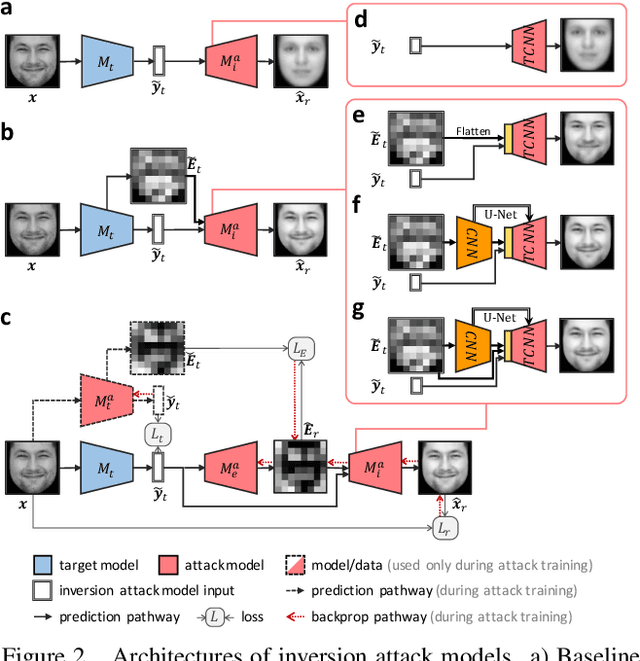

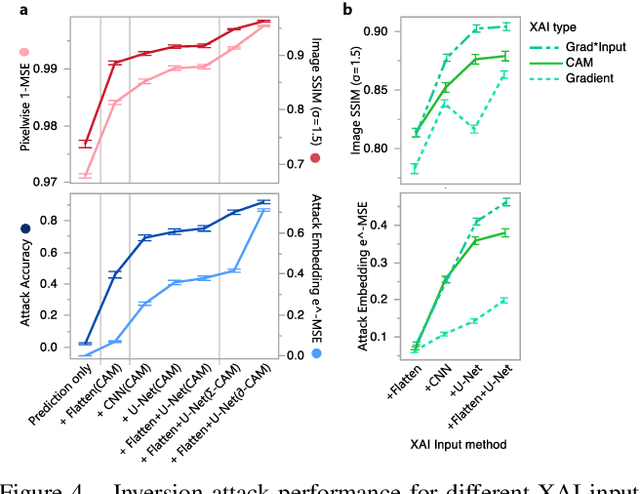
The successful deployment of artificial intelligence (AI) in many domains from healthcare to hiring requires their responsible use, particularly in model explanations and privacy. Explainable artificial intelligence (XAI) provides more information to help users to understand model decisions, yet this additional knowledge exposes additional risks for privacy attacks. Hence, providing explanation harms privacy. We study this risk for image-based model inversion attacks and identified several attack architectures with increasing performance to reconstruct private image data from model explanations. We have developed several multi-modal transposed CNN architectures that achieve significantly higher inversion performance than using the target model prediction only. These XAI-aware inversion models were designed to exploit the spatial knowledge in image explanations. To understand which explanations have higher privacy risk, we analyzed how various explanation types and factors influence inversion performance. In spite of some models not providing explanations, we further demonstrate increased inversion performance even for non-explainable target models by exploiting explanations of surrogate models through attention transfer. This method first inverts an explanation from the target prediction, then reconstructs the target image. These threats highlight the urgent and significant privacy risks of explanations and calls attention for new privacy preservation techniques that balance the dual-requirement for AI explainability and privacy.