 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVPruner: Structural Pruning for Faster and Memory-Efficient Large Language Models
Sep 17, 2024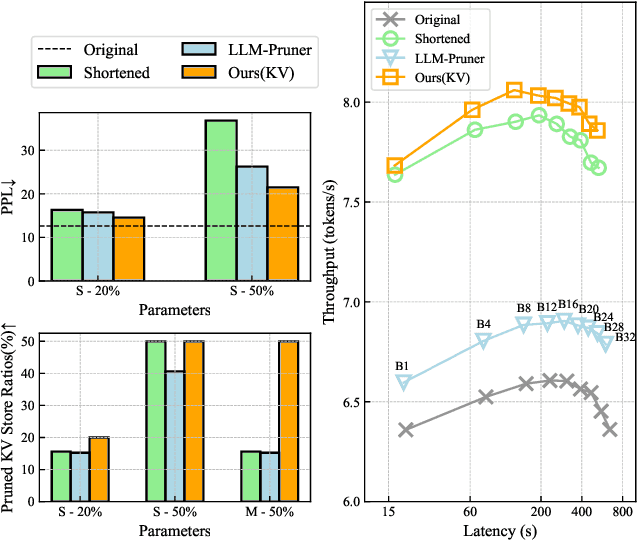
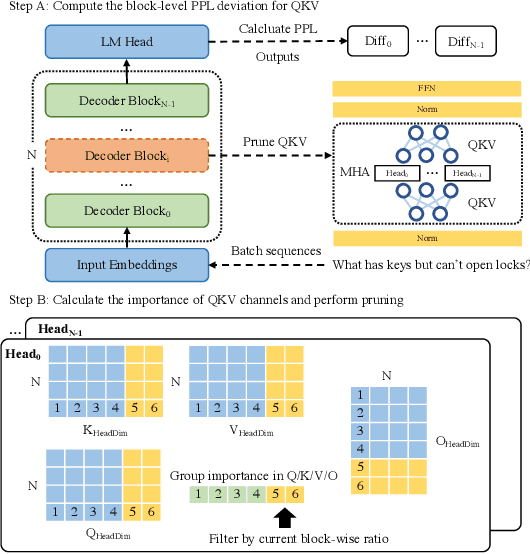
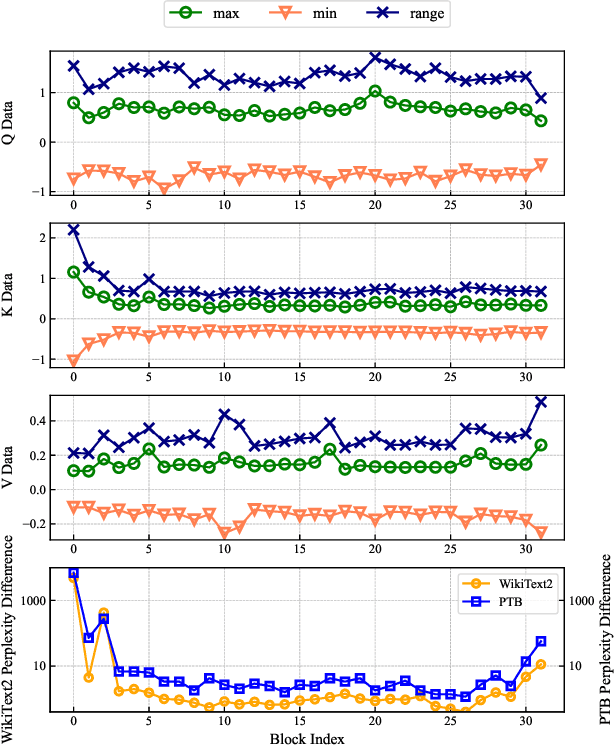
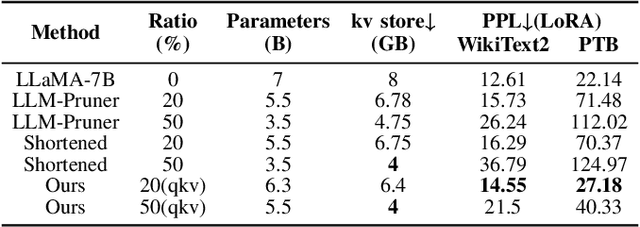
The bottleneck associated with the key-value(KV) cache presents a significant challenge during the inference processes of large language models. While depth pruning accelerates inference, it requires extensive recovery training, which can take up to two weeks. On the other hand, width pruning retains much of the performance but offers slight speed gains. To tackle these challenges, we propose KVPruner to improve model efficiency while maintaining performance. Our method uses global perplexity-based analysis to determine the importance ratio for each block and provides multiple strategies to prune non-essential KV channels within blocks. Compared to the original model, KVPruner reduces runtime memory usage by 50% and boosts throughput by over 35%. Additionally, our method requires only two hours of LoRA fine-tuning on small datasets to recover most of the performance.