 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-CAM: Cluster-Weighted Visual Interpretation of CNNs' Decision in Image Classification
Feb 03, 2023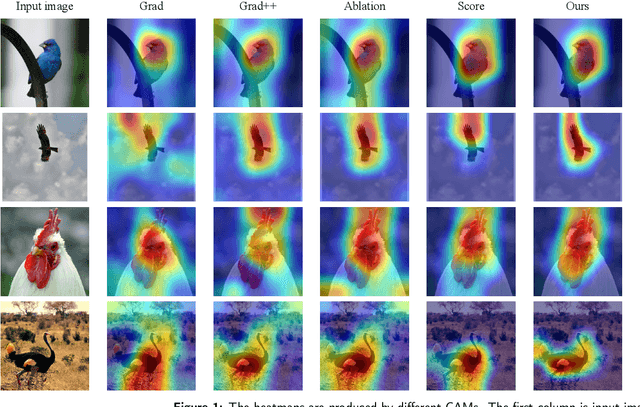
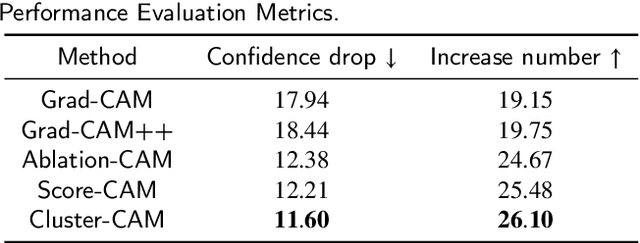
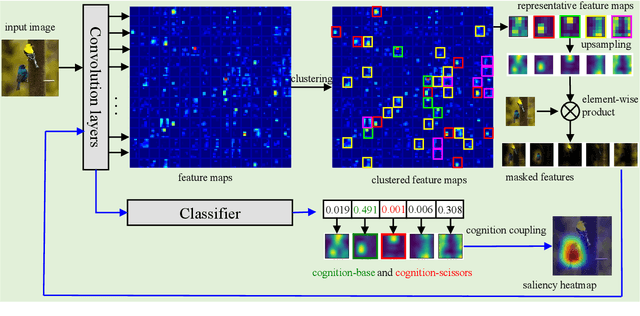
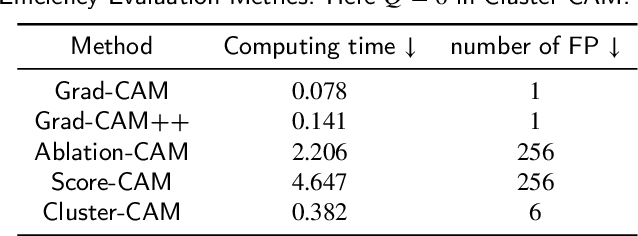
Despite the tremendous success of convolutional neural networks (CNNs) in computer vision, the mechanism of CNNs still lacks clear interpretation. Currently, class activation mapping (CAM), a famous visualization technique to interpret CNN's decision, has drawn increasing attention. Gradient-based CAMs are efficient while the performance is heavily affected by gradient vanishing and exploding. In contrast, gradient-free CAMs can avoid computing gradients to produce more understandable results. However, existing gradient-free CAMs are quite time-consuming because hundreds of forward interference per image are required. In this paper, we proposed Cluster-CAM, an effective and efficient gradient-free CNN interpretation algorithm. Cluster-CAM can significantly reduce the times of forward propagation by splitting the feature maps into clusters in an unsupervised manner. Furthermore, we propose an artful strategy to forge a cognition-base map and cognition-scissors from clustered feature maps. The final salience heatmap will be computed by merging the above cognition maps. Qualitative results conspicuously show that Cluster-CAM can produce heatmaps where the highlighted regions match the human's cognition more precisely than existing CAMs. The quantitative evaluation further demonstrates the superiority of Cluster-CAM in both effectiveness and efficiency.
VS-CAM: Vertex Semantic Class Activation Mapping to Interpret Vision Graph Neural Network
Sep 15, 2022

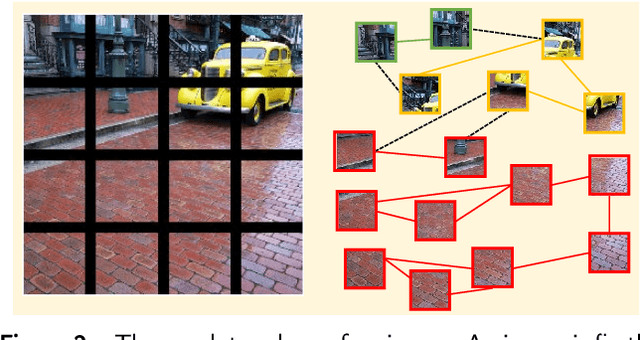

Graph convolutional neural network (GCN) has drawn increasing attention and attained good performance in various computer vision tasks, however, there lacks a clear interpretation of GCN's inner mechanism. For standard convolutional neural networks (CNNs), class activation mapping (CAM) methods are commonly used to visualize the connection between CNN's decision and image region by generating a heatmap. Nonetheless, such heatmap usually exhibits semantic-chaos when these CAMs are applied to GCN directly. In this paper, we proposed a novel visualization method particularly applicable to GCN, Vertex Semantic Class Activation Mapping (VS-CAM). VS-CAM includes two independent pipelines to produce a set of semantic-probe maps and a semantic-base map, respectively. Semantic-probe maps are used to detect the semantic information from semantic-base map to aggregate a semantic-aware heatmap. Qualitative results show that VS-CAM can obtain heatmaps where the highlighted regions match the objects much more precisely than CNN-based CAM. The quantitative evaluation further demonstrates the superiority of VS-CAM.