 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRFCBF: enhance the performance and stability of Fast Correlation-Based Filter
May 30, 2021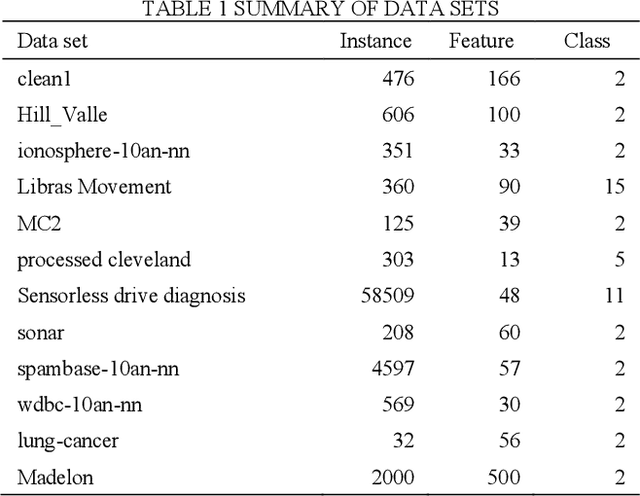
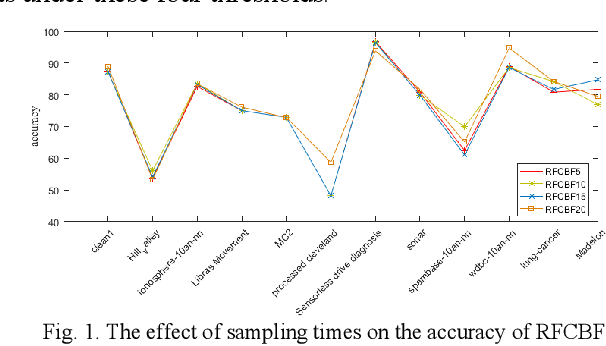
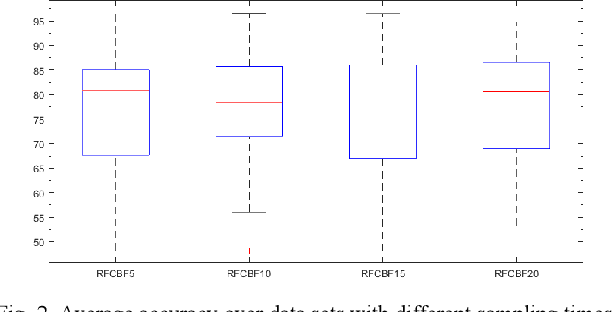

Feature selection is a preprocessing step which plays a crucial role in the domain of machine learning and data mining. Feature selection methods have been shown to be effctive in removing redundant and irrelevant features, improving the learning algorithm's prediction performance. Among the various methods of feature selection based on redundancy, the fast correlation-based filter (FCBF) is one of the most effective. In this paper, we proposed a novel extension of FCBF, called RFCBF, which combines resampling technique to improve classification accuracy. We performed comprehensive experiments to compare the RFCBF with other state-of-the-art feature selection methods using the KNN classifier on 12 publicly available data sets. The experimental results show that the RFCBF algorithm yields significantly better results than previous state-of-the-art methods in terms of classification accuracy and runtime.
Hybrid gene selection approach using XGBoost and multi-objective genetic algorithm for cancer classification
May 30, 2021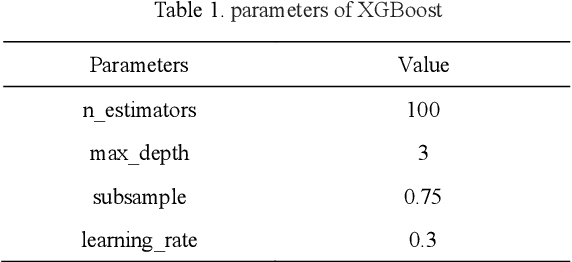
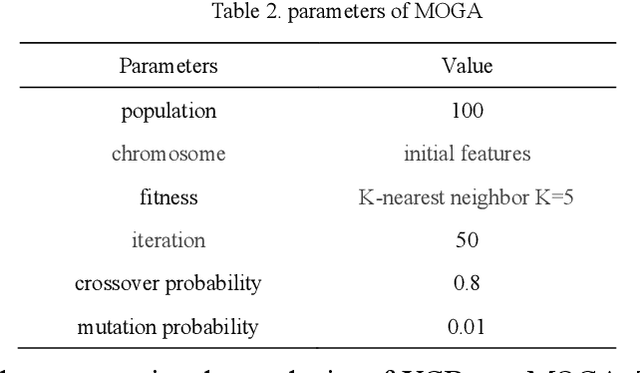
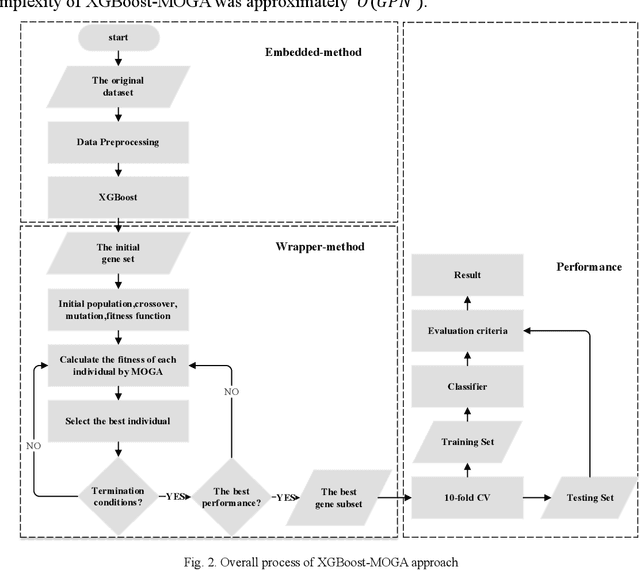
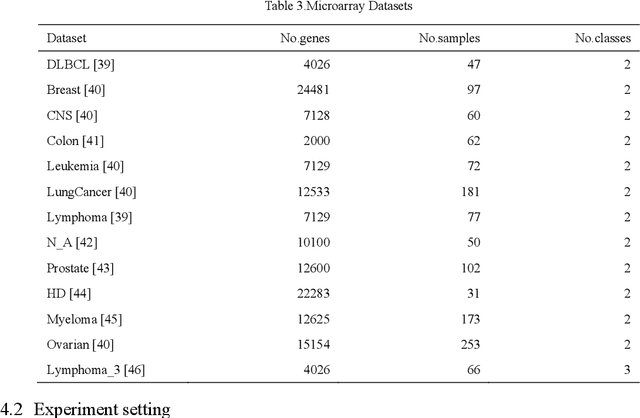
Microarray gene expression data are often accompanied by a large number of genes and a small number of samples. However, only a few of these genes are relevant to cancer, resulting in signigicant gene selection challenges. Hence, we propose a two-stage gene selection approach by combining extreme gradient boosting (XGBoost) and a multi-objective optimization genetic algorithm (XGBoost-MOGA) for cancer classification in microarray datasets. In the first stage, the genes are ranked use an ensemble-based feature selection using XGBoost. This stage can effectively remove irrelevant genes and yield a group comprising the most relevant genes related to the class. In the second stage, XGBoost-MOGA searches for an optimal gene subset based on the most relevant genes's group using a multi-objective optimization genetic algorithm. We performed comprehensive experiments to compare XGBoost-MOGA with other state-of-the-art feature selection methods using two well-known learning classifiers on 13 publicly available microarray expression datasets. The experimental results show that XGBoost-MOGA yields significantly better results than previous state-of-the-art algorithms in terms of various evaluation criteria, such as accuracy, F-score, precision, and recall.