 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupLink: An End-to-end Multitask Method for Word Grouping and Relation Extraction in Form Understanding
May 10, 2021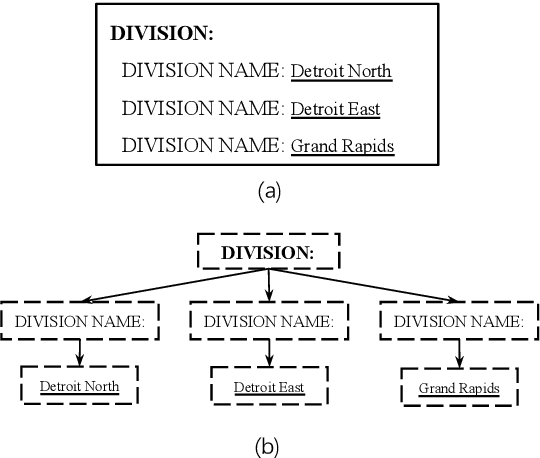
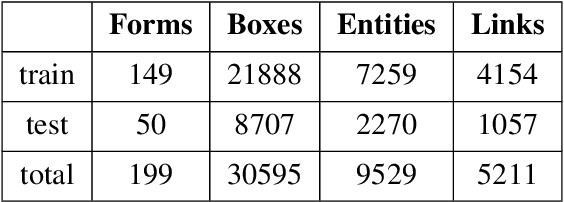
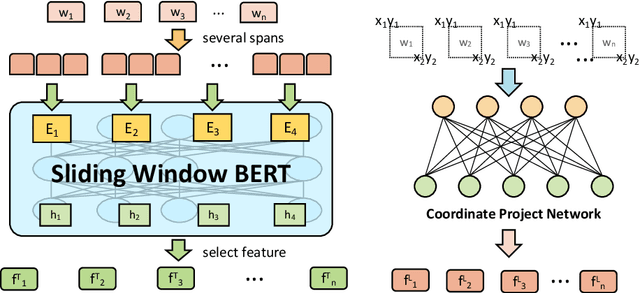
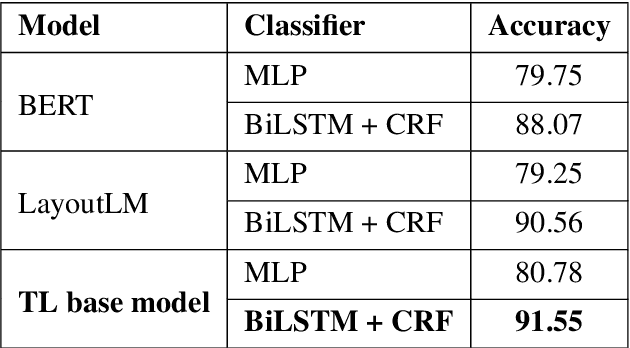
Forms are a common type of document in real life and carry rich information through textual contents and the organizational structure. To realize automatic processing of forms, word grouping and relation extraction are two fundamental and crucial steps after preliminary processing of optical character reader (OCR). Word grouping is to aggregate words that belong to the same semantic entity, and relation extraction is to predict the links between semantic entities. Existing works treat them as two individual tasks, but these two tasks are correlated and can reinforce each other. The grouping process will refine the integrated representation of the corresponding entity, and the linking process will give feedback to the grouping performance. For this purpose, we acquire multimodal features from both textual data and layout information and build an end-to-end model through multitask training to combine word grouping and relation extraction to enhance performance on each task. We validate our proposed method on a real-world, fully-annotated, noisy-scanned benchmark, FUNSD, and extensive experiments demonstrate the effectiveness of our method.