 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAME: Forecastability-Aware Mixture of Experts for Heterogeneous Time Series Forecasting
Jun 08, 2026Large-scale retail and industrial forecasting systems contain many heterogeneous time series whose lifecycle, sparsity, volatility, seasonality, spectral patterns, and contextual sensitivity differ substantially. A single forecasting model rarely performs well across all regimes, while dense ensembles increase inference cost and provide limited insight into expert suitability. This paper studies forecastability-aware expert routing: learning how data characteristics determine the suitability of forecasting experts. We propose \method{}, a sparse mixture-of-experts framework that represents each series with a multidimensional forecastability fingerprint, mines expert-suitability targets from validation performance, and trains a cost-aware sparse router to activate a small budgeted set of experts for each series. Using a production-scale vending-machine sales dataset from Shandong New Beiyang (SNBC), where the forecasting component has been integrated into the replenishment-planning pipeline, together with public retail benchmarks, we show that expert suitability varies systematically across data regimes. On the industrial dataset with 5,000+ machines and 60M+ transactions, \method{} Top-2 reduces MSE by 12.4\% over the strongest single expert, LightGBM, while executing 1.92 experts per series on average. The deployed component produces demand forecasts, while inventory-oriented gains are estimated by an offline replay simulator under a fixed replenishment policy rather than by online intervention. The framework turns heterogeneous sales forecasting from heuristic model selection into data mining of forecastability patterns and expert specialization. Code is available at https://github.com/hit636/FAME
ASGMamba: Adaptive Spectral Gating Mamba for Multivariate Time Series Forecasting
Feb 02, 2026Long-term multivariate time series forecasting (LTSF) plays a crucial role in various high-performance computing applications, including real-time energy grid management and large-scale traffic flow simulation. However, existing solutions face a dilemma: Transformer-based models suffer from quadratic complexity, limiting their scalability on long sequences, while linear State Space Models (SSMs) often struggle to distinguish valuable signals from high-frequency noise, leading to wasted state capacity. To bridge this gap, we propose ASGMamba, an efficient forecasting framework designed for resource-constrained supercomputing environments. ASGMamba integrates a lightweight Adaptive Spectral Gating (ASG) mechanism that dynamically filters noise based on local spectral energy, enabling the Mamba backbone to focus its state evolution on robust temporal dynamics. Furthermore, we introduce a hierarchical multi-scale architecture with variable-specific Node Embeddings to capture diverse physical characteristics. Extensive experiments on nine benchmarks demonstrate that ASGMamba achieves state-of-the-art accuracy. While keeping strictly $$\mathcal{O}(L)$$ complexity we significantly reduce the memory usage on long-horizon tasks, thus establishing ASGMamba as a scalable solution for high-throughput forecasting in resource limited environments.The code is available at https://github.com/hit636/ASGMamba
AWEMixer: Adaptive Wavelet-Enhanced Mixer Network for Long-Term Time Series Forecasting
Nov 06, 2025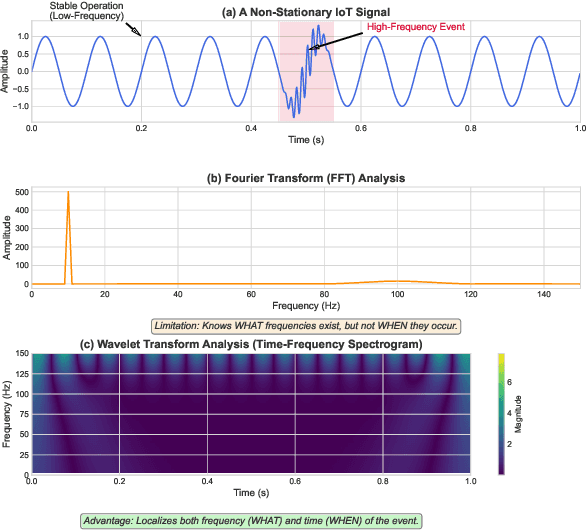
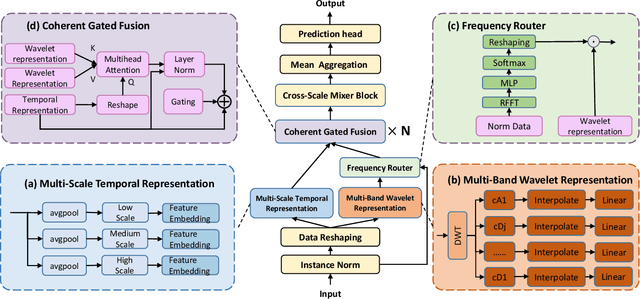
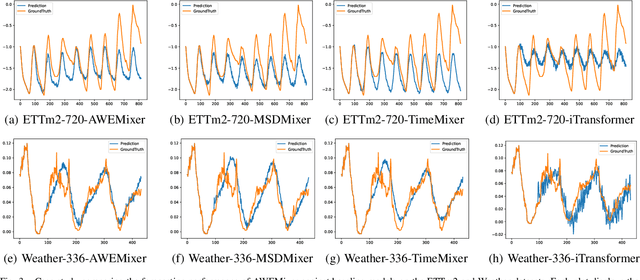
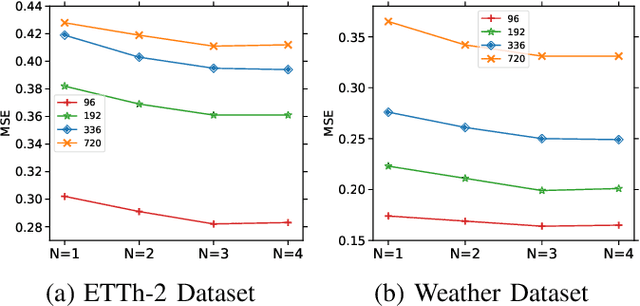
Forecasting long-term time series in IoT environments remains a significant challenge due to the non-stationary and multi-scale characteristics of sensor signals. Furthermore, error accumulation causes a decrease in forecast quality when predicting further into the future. Traditional methods are restricted to operate in time-domain, while the global frequency information achieved by Fourier transform would be regarded as stationary signals leading to blur the temporal patterns of transient events. We propose AWEMixer, an Adaptive Wavelet-Enhanced Mixer Network including two innovative components: 1) a Frequency Router designs to utilize the global periodicity pattern achieved by Fast Fourier Transform to adaptively weight localized wavelet subband, and 2) a Coherent Gated Fusion Block to achieve selective integration of prominent frequency features with multi-scale temporal representation through cross-attention and gating mechanism, which realizes accurate time-frequency localization while remaining robust to noise. Seven public benchmarks validate that our model is more effective than recent state-of-the-art models. Specifically, our model consistently achieves performance improvement compared with transformer-based and MLP-based state-of-the-art models in long-sequence time series forecasting. Code is available at https://github.com/hit636/AWEMixer
DPANet: Dual Pyramid Attention Network for Multivariate Time Series Forecasting
Sep 18, 2025We conducted rigorous ablation studies to validate DPANet's key components (Table \ref{tab:ablation-study}). The full model consistently outperforms all variants. To test our dual-domain hypothesis, we designed two specialized versions: a Temporal-Only model (fusing two identical temporal pyramids) and a Frequency-Only model (fusing two spectral pyramids). Both variants underperformed significantly, confirming that the fusion of heterogeneous temporal and frequency information is critical. Furthermore, replacing the cross-attention mechanism with a simpler method (w/o Cross-Fusion) caused the most severe performance degradation. This result underscores that our interactive fusion block is the most essential component.
NQKV: A KV Cache Quantization Scheme Based on Normal Distribution Characteristics
May 22, 2025Large Language Models (LLMs) have demonstrated remarkable proficiency across a wide range of tasks. However, LLMs often require larger batch sizes to enhance throughput or longer context lengths to meet task demands, which significantly increases the memory resource consumption of the Key-Value (KV) cache during inference, becoming a major bottleneck in LLM deployment. To address this issue, quantization is a common and straightforward approach. Currently, quantization methods for activations are limited to 8-bit, and quantization to even lower bits can lead to substantial accuracy drops. To further save space by quantizing the KV cache to even lower bits, we analyzed the element distribution of the KV cache and designed the NQKV algorithm. Since the elements within each block of the KV cache follow a normal distribution, NQKV employs per-block quantile quantization to achieve information-theoretically optimal quantization error. Without significantly compromising model output quality, NQKV enables the OPT model to perform inference with an 2x larger batch size or a 4x longer context length, and it improves throughput by 9.3x compared to when the KV cache is not used.
Adaptive Rectification Sampling for Test-Time Compute Scaling
Apr 02, 2025The newly released OpenAI-o1 and DeepSeek-R1 have demonstrated that test-time scaling can significantly improve model performance, especially in complex tasks such as logical reasoning. Common test-time scaling methods involve generating more chain of thoughts (CoTs) or longer CoTs with self-correction. However, while self-correction can improve performance, it may lead to significant token waste and reduce readability of the CoT if the reasoning steps are already correct. To demonstrate that large language models (LLMs) can rectify errors at a more fine-grained level, we propose Adaptive Rectification Sampling (AR-Sampling), which can guide the LLMs to self-correction at the appropriate step. AR-Sampling leverages a process-supervised reward model (PRM) as a verifier and constructed trigger sentences to guide the model in adaptive step-level rethinking. Through the experiments on GSM8K and MATH500, it indicate that our approach enables the models to rethink in more fine-grained level, improving the accuracy of solutions, while generating a reasonable number of additional tokens.
BEND: Bagging Deep Learning Training Based on Efficient Neural Network Diffusion
Mar 23, 2024
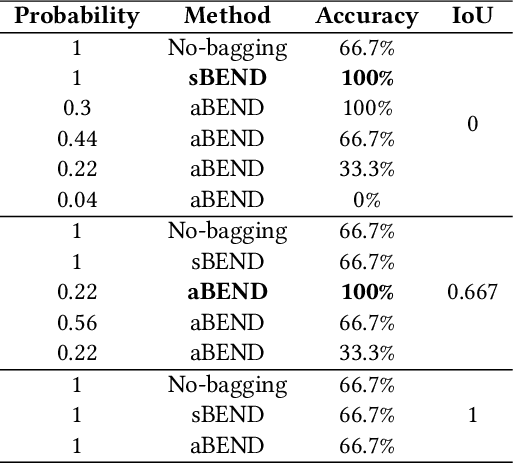
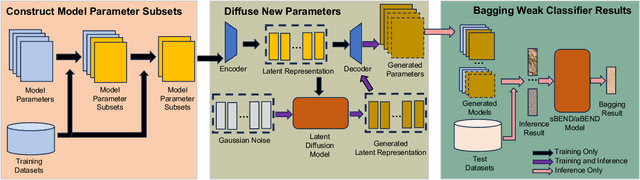

Bagging has achieved great success in the field of machine learning by integrating multiple base classifiers to build a single strong classifier to reduce model variance. The performance improvement of bagging mainly relies on the number and diversity of base classifiers. However, traditional deep learning model training methods are expensive to train individually and difficult to train multiple models with low similarity in a restricted dataset. Recently, diffusion models, which have been tremendously successful in the fields of imaging and vision, have been found to be effective in generating neural network model weights and biases with diversity. We creatively propose a Bagging deep learning training algorithm based on Efficient Neural network Diffusion (BEND). The originality of BEND comes from the first use of a neural network diffusion model to efficiently build base classifiers for bagging. Our approach is simple but effective, first using multiple trained model weights and biases as inputs to train autoencoder and latent diffusion model to realize a diffusion model from noise to valid neural network parameters. Subsequently, we generate several base classifiers using the trained diffusion model. Finally, we integrate these ba se classifiers for various inference tasks using the Bagging method. Resulting experiments on multiple models and datasets show that our proposed BEND algorithm can consistently outperform the mean and median accuracies of both the original trained model and the diffused model. At the same time, new models diffused using the diffusion model have higher diversity and lower cost than multiple models trained using traditional methods. The BEND approach successfully introduces diffusion models into the new deep learning training domain and provides a new paradigm for future deep learning training and inference.