Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMe: An Accurate Maximum Entropy Method for Efficient Approximations in Large-Scale Machine Learning
Jun 03, 2019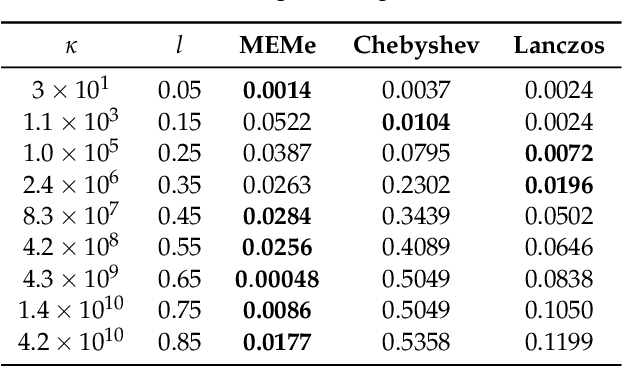
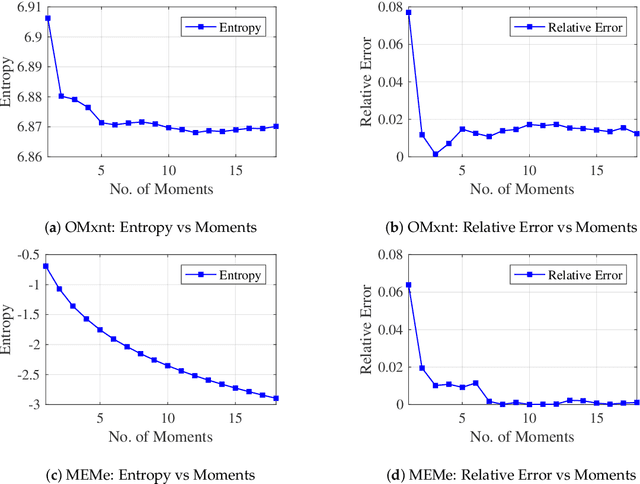
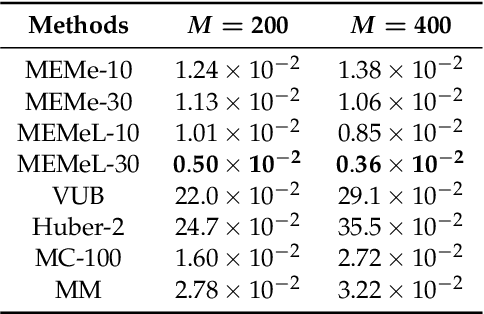
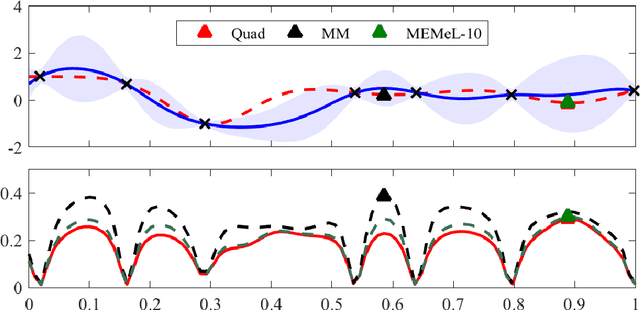
Efficient approximation lies at the heart of large-scale machine learning problems. In this paper, we propose a novel, robust maximum entropy algorithm, which is capable of dealing with hundreds of moments and allows for computationally efficient approximations. We showcase the usefulness of the proposed method, its equivalence to constrained Bayesian variational inference and demonstrate its superiority over existing approaches in two applications, namely, fast log determinant estimation and information-theoretic Bayesian optimisation.
* MEMe: An Accurate Maximum Entropy Method for Efficient
Approximations in Large-Scale Machine Learning. Entropy, 21(6), 551 (2019)
* 18 pages, 3 figures, Published at Entropy 2019: Special Issue Entropy Based Inference and Optimization in Machine Learning
* 18 pages, 3 figures, Published at Entropy 2019: Special Issue Entropy Based Inference and Optimization in Machine Learning
Via