 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Power Laws in Entity Length
Dec 02, 2018
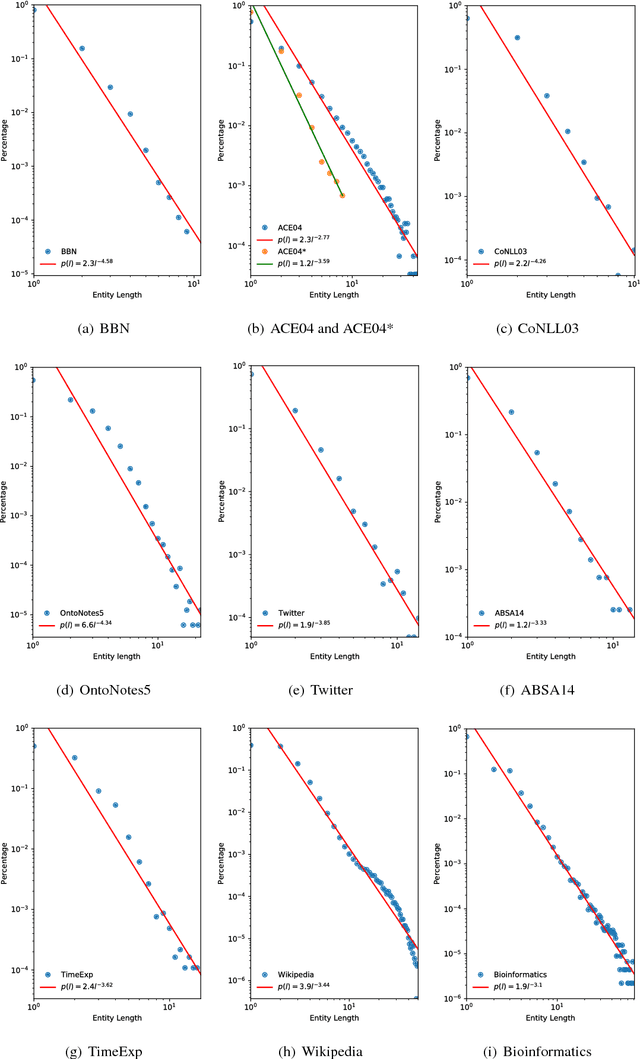
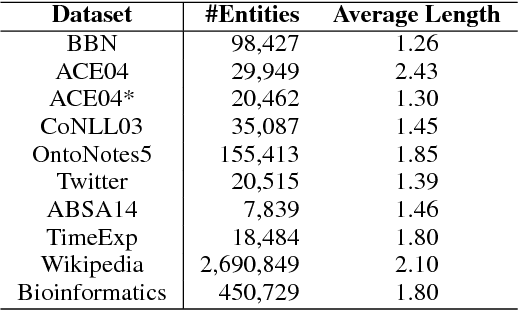
This paper presents a discovery that the length of the entities in various datasets follows a family of scale-free power law distributions. The concept of entity here broadly includes the named entity, entity mention, time expression, aspect term, and domain-specific entity that are well investigated in natural language processing and related areas. The entity length denotes the number of words in an entity. The power law distributions in entity length possess the scale-free property and have well-defined means and finite variances. We explain the phenomenon of power laws in entity length by the principle of least effort in communication and the preferential mechanism.
Named Entity Analysis and Extraction with Uncommon Words
Oct 16, 2018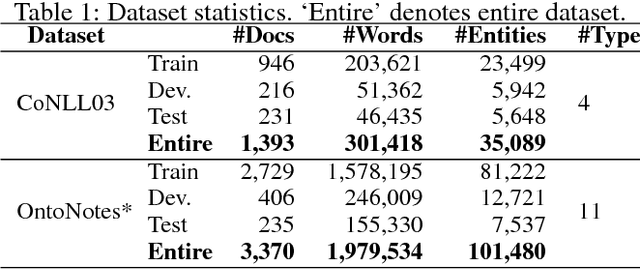
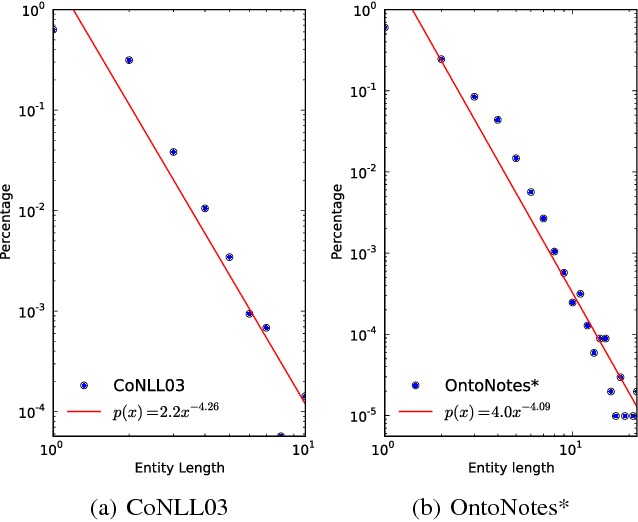

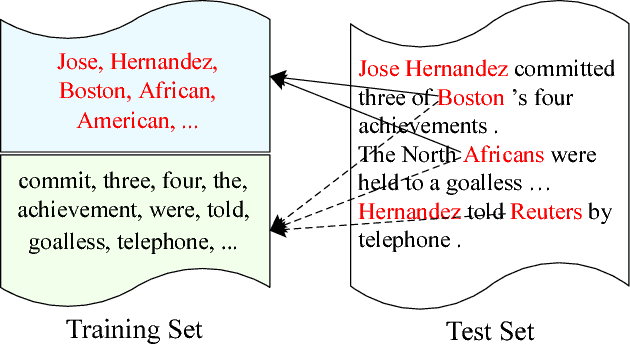
Most previous research treats named entity extraction and classification as an end-to-end task. We argue that the two sub-tasks should be addressed separately. Entity extraction lies at the level of syntactic analysis while entity classification lies at the level of semantic analysis. According to Noam Chomsky's "Syntactic Structures," pp. 93-94 (Chomsky 1957), syntax is not appealed to semantics and semantics does not affect syntax. We analyze two benchmark datasets for the characteristics of named entities, finding that uncommon words can distinguish named entities from common text; where uncommon words are the words that hardly appear in common text and they are mainly the proper nouns. Experiments validate that lexical and syntactic features achieve state-of-the-art performance on entity extraction and that semantic features do not further improve the extraction performance, in both of our model and the state-of-the-art baselines. With Chomsky's view, we also explain the failure of joint syntactic and semantic parsings in other works.