 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRR4Covid: Learning Automated COVID-19 Infection Segmentation from Digitally Reconstructed Radiographs
Aug 26, 2020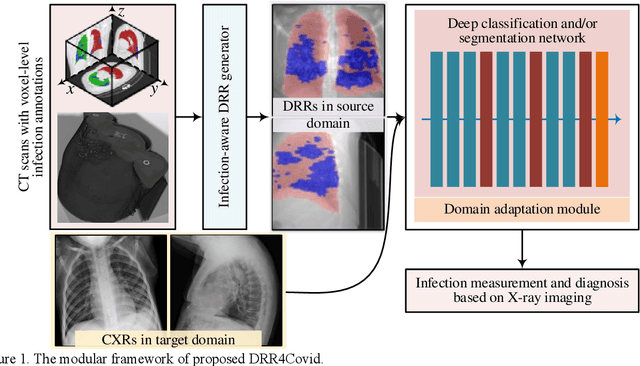

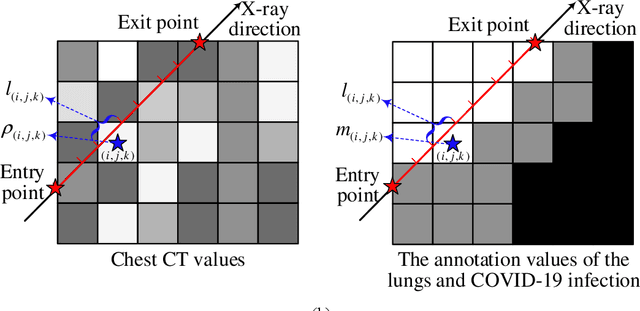

Automated infection measurement and COVID-19 diagnosis based on Chest X-ray (CXR) imaging is important for faster examination. We propose a novel approach, called DRR4Covid, to learn automated COVID-19 diagnosis and infection segmentation on CXRs from digitally reconstructed radiographs (DRRs). DRR4Covid comprises of an infection-aware DRR generator, a classification and/or segmentation network, and a domain adaptation module. The infection-aware DRR generator is able to produce DRRs with adjustable strength of radiological signs of COVID-19 infection, and generate pixel-level infection annotations that match the DRRs precisely. The domain adaptation module is introduced to reduce the domain discrepancy between DRRs and CXRs by training networks on unlabeled real CXRs and labeled DRRs together.We provide a simple but effective implementation of DRR4Covid by using a domain adaptation module based on Maximum Mean Discrepancy (MMD), and a FCN-based network with a classification header and a segmentation header. Extensive experiment results have confirmed the efficacy of our method; specifically, quantifying the performance by accuracy, AUC and F1-score, our network without using any annotations from CXRs has achieved a classification score of (0.954, 0.989, 0.953) and a segmentation score of (0.957, 0.981, 0.956) on a test set with 794 normal cases and 794 positive cases. Besides, we estimate the sensitive of X-ray images in detecting COVID-19 infection by adjusting the strength of radiological signs of COVID-19 infection in synthetic DRRs. The estimated detection limit of the proportion of infected voxels in the lungs is 19.43%, and the estimated lower bound of the contribution rate of infected voxels is 20.0% for significant radiological signs of COVID-19 infection. Our codes will be made publicly available at https://github.com/PengyiZhang/DRR4Covid.
Learning Diagnosis of COVID-19 from a Single Radiological Image
Jun 06, 2020
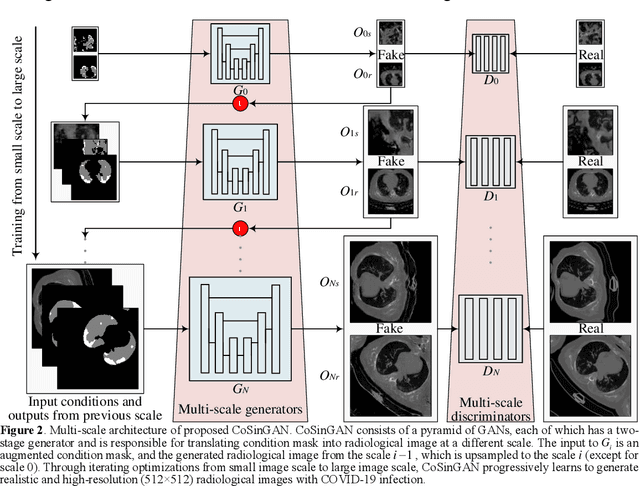


Radiological image is currently adopted as the visual evidence for COVID-19 diagnosis in clinical. Using deep models to realize automated infection measurement and COVID-19 diagnosis is important for faster examination based on radiological imaging. Unfortunately, collecting large training data systematically in the early stage is difficult. To address this problem, we explore the feasibility of learning deep models for COVID-19 diagnosis from a single radiological image by resorting to synthesizing diverse radiological images. Specifically, we propose a novel conditional generative model, called CoSinGAN, which can be learned from a single radiological image with a given condition, i.e., the annotations of the lung and COVID-19 infection. Our CoSinGAN is able to capture the conditional distribution of visual finds of COVID-19 infection, and further synthesize diverse and high-resolution radiological images that match the input conditions precisely. Both deep classification and segmentation networks trained on synthesized samples from CoSinGAN achieve notable detection accuracy of COVID-19 infection. Such results are significantly better than the counterparts trained on the same extremely small number of real samples (1 or 2 real samples) by using strong data augmentation, and approximate to the counterparts trained on large dataset (2846 real images). It confirms our method can significantly reduce the performance gap between deep models trained on extremely small dataset and on large dataset, and thus has the potential to realize learning COVID-19 diagnosis from few radiological images in the early stage of COVID-19 pandemic. Our codes are made publicly available at https://github.com/PengyiZhang/CoSinGAN.
ACCL: Adversarial constrained-CNN loss for weakly supervised medical image segmentation
May 01, 2020
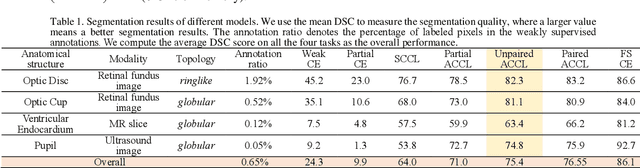
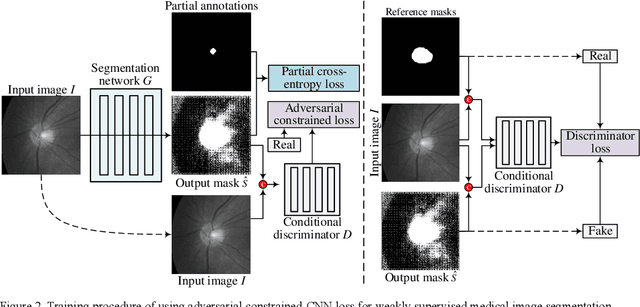

We propose adversarial constrained-CNN loss, a new paradigm of constrained-CNN loss methods, for weakly supervised medical image segmentation. In the new paradigm, prior knowledge is encoded and depicted by reference masks, and is further employed to impose constraints on segmentation outputs through adversarial learning with reference masks. Unlike pseudo label methods for weakly supervised segmentation, such reference masks are used to train a discriminator rather than a segmentation network, and thus are not required to be paired with specific images. Our new paradigm not only greatly facilitates imposing prior knowledge on network's outputs, but also provides stronger and higher-order constraints, i.e., distribution approximation, through adversarial learning. Extensive experiments involving different medical modalities, different anatomical structures, different topologies of the object of interest, different levels of prior knowledge and weakly supervised annotations with different annotation ratios is conducted to evaluate our ACCL method. Consistently superior segmentation results over the size constrained-CNN loss method have been achieved, some of which are close to the results of full supervision, thus fully verifying the effectiveness and generalization of our method. Specifically, we report an average Dice score of 75.4% with an average annotation ratio of 0.65%, surpassing the prior art, i.e., the size constrained-CNN loss method, by a large margin of 11.4%. Our codes are made publicly available at https://github.com/PengyiZhang/ACCL.
A Survey on Deep Learning of Small Sample in Biomedical Image Analysis
Aug 01, 2019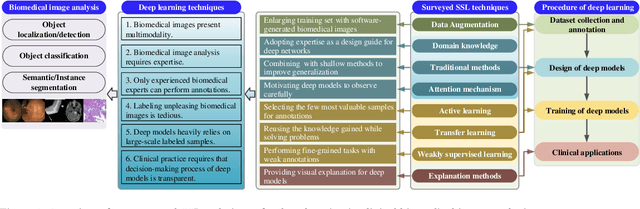

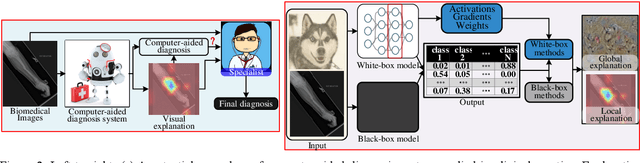

The success of deep learning has been witnessed as a promising technique for computer-aided biomedical image analysis, due to end-to-end learning framework and availability of large-scale labelled samples. However, in many cases of biomedical image analysis, deep learning techniques suffer from the small sample learning (SSL) dilemma caused mainly by lack of annotations. To be more practical for biomedical image analysis, in this paper we survey the key SSL techniques that help relieve the suffering of deep learning by combining with the development of related techniques in computer vision applications. In order to accelerate the clinical usage of biomedical image analysis based on deep learning techniques, we intentionally expand this survey to include the explanation methods for deep models that are important to clinical decision making. We survey the key SSL techniques by dividing them into five categories: (1) explanation techniques, (2) weakly supervised learning techniques, (3) transfer learning techniques, (4) active learning techniques, and (5) miscellaneous techniques involving data augmentation, domain knowledge, traditional shallow methods and attention mechanism. These key techniques are expected to effectively support the application of deep learning in clinical biomedical image analysis, and furtherly improve the analysis performance, especially when large-scale annotated samples are not available. We bulid demos at https://github.com/PengyiZhang/MIADeepSSL.
SlimYOLOv3: Narrower, Faster and Better for Real-Time UAV Applications
Jul 25, 2019



Drones or general Unmanned Aerial Vehicles (UAVs), endowed with computer vision function by on-board cameras and embedded systems, have become popular in a wide range of applications. However, real-time scene parsing through object detection running on a UAV platform is very challenging, due to limited memory and computing power of embedded devices. To deal with these challenges, in this paper we propose to learn efficient deep object detectors through channel pruning of convolutional layers. To this end, we enforce channel-level sparsity of convolutional layers by imposing L1 regularization on channel scaling factors and prune less informative feature channels to obtain "slim" object detectors. Based on such approach, we present SlimYOLOv3 with fewer trainable parameters and floating point operations (FLOPs) in comparison of original YOLOv3 (Joseph Redmon et al., 2018) as a promising solution for real-time object detection on UAVs. We evaluate SlimYOLOv3 on VisDrone2018-Det benchmark dataset; compelling results are achieved by SlimYOLOv3 in comparison of unpruned counterpart, including ~90.8% decrease of FLOPs, ~92.0% decline of parameter size, running ~2 times faster and comparable detection accuracy as YOLOv3. Experimental results with different pruning ratios consistently verify that proposed SlimYOLOv3 with narrower structure are more efficient, faster and better than YOLOv3, and thus are more suitable for real-time object detection on UAVs. Our codes are made publicly available at https://github.com/PengyiZhang/SlimYOLOv3.