 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Distributed Approach towards Discriminative Distance Metric Learning
May 11, 2019


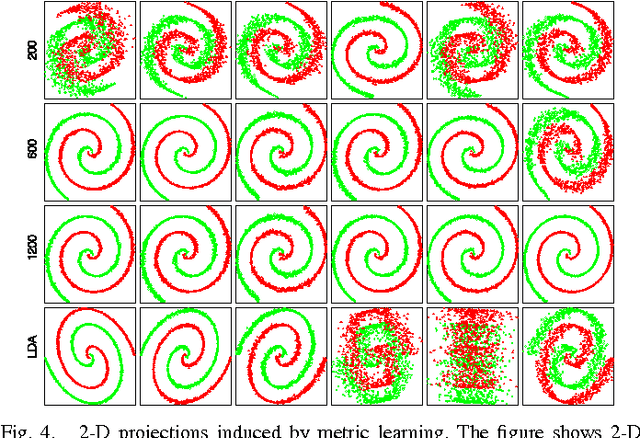
Distance metric learning is successful in discovering intrinsic relations in data. However, most algorithms are computationally demanding when the problem size becomes large. In this paper, we propose a discriminative metric learning algorithm, and develop a distributed scheme learning metrics on moderate-sized subsets of data, and aggregating the results into a global solution. The technique leverages the power of parallel computation. The algorithm of the aggregated distance metric learning (ADML) scales well with the data size and can be controlled by the partition. We theoretically analyse and provide bounds for the error induced by the distributed treatment. We have conducted experimental evaluation of ADML, both on specially designed tests and on practical image annotation tasks. Those tests have shown that ADML achieves the state-of-the-art performance at only a fraction of the cost incurred by most existing methods.