 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLANDMARK: Language-guided Representation Enhancement Framework for Scene Graph Generation
Mar 02, 2023Scene graph generation (SGG) is a sophisticated task that suffers from both complex visual features and dataset long-tail problem. Recently, various unbiased strategies have been proposed by designing novel loss functions and data balancing strategies. Unfortunately, these unbiased methods fail to emphasize language priors in feature refinement perspective. Inspired by the fact that predicates are highly correlated with semantics hidden in subject-object pair and global context, we propose LANDMARK (LANguage-guiDed representationenhanceMent frAmewoRK) that learns predicate-relevant representations from language-vision interactive patterns, global language context and pair-predicate correlation. Specifically, we first project object labels to three distinctive semantic embeddings for different representation learning. Then, Language Attention Module (LAM) and Experience Estimation Module (EEM) process subject-object word embeddings to attention vector and predicate distribution, respectively. Language Context Module (LCM) encodes global context from each word embed-ding, which avoids isolated learning from local information. Finally, modules outputs are used to update visual representations and SGG model's prediction. All language representations are purely generated from object categories so that no extra knowledge is needed. This framework is model-agnostic and consistently improves performance on existing SGG models. Besides, representation-level unbiased strategies endow LANDMARK the advantage of compatibility with other methods. Code is available at https://github.com/rafa-cxg/PySGG-cxg.
Biasing Like Human: A Cognitive Bias Framework for Scene Graph Generation
Mar 17, 2022
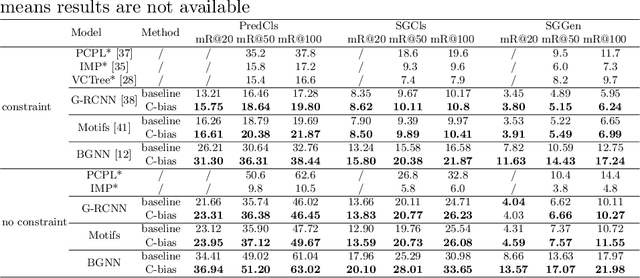
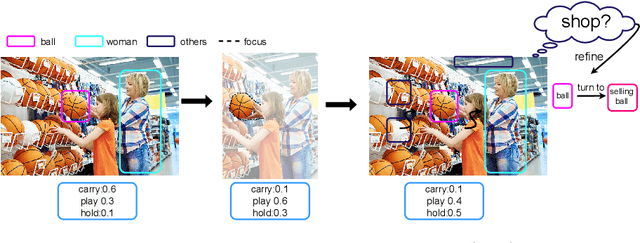
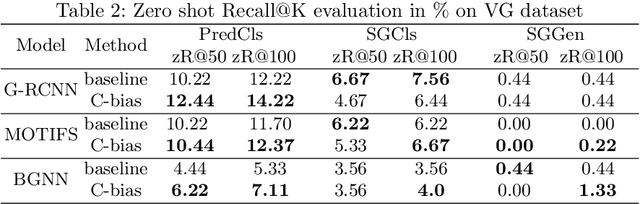
Scene graph generation is a sophisticated task because there is no specific recognition pattern (e.g., "looking at" and "near" have no conspicuous difference concerning vision, whereas "near" could occur between entities with different morphology). Thus some scene graph generation methods are trapped into most frequent relation predictions caused by capricious visual features and trivial dataset annotations. Therefore, recent works emphasized the "unbiased" approaches to balance predictions for a more informative scene graph. However, human's quick and accurate judgments over relations between numerous objects should be attributed to "bias" (i.e., experience and linguistic knowledge) rather than pure vision. To enhance the model capability, inspired by the "cognitive bias" mechanism, we propose a novel 3-paradigms framework that simulates how humans incorporate the label linguistic features as guidance of vision-based representations to better mine hidden relation patterns and alleviate noisy visual propagation. Our framework is model-agnostic to any scene graph model. Comprehensive experiments prove our framework outperforms baseline modules in several metrics with minimum parameters increment and achieves new SOTA performance on Visual Genome dataset.