 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimited-angle x-ray nano-tomography with machine-learning enabled iterative reconstruction engine
Mar 25, 2025



A long-standing challenge in tomography is the 'missing wedge' problem, which arises when the acquisition of projection images within a certain angular range is restricted due to geometrical constraints. This incomplete dataset results in significant artifacts and poor resolution in the reconstructed image. To tackle this challenge, we propose an approach dubbed Perception Fused Iterative Tomography Reconstruction Engine, which integrates a convolutional neural network (CNN) with perceptional knowledge as a smart regularizer into an iterative solving engine. We employ the Alternating Direction Method of Multipliers to optimize the solution in both physics and image domains, thereby achieving a physically coherent and visually enhanced result. We demonstrate the effectiveness of the proposed approach using various experimental datasets obtained with different x-ray microscopy techniques. All show significantly improved reconstruction even with a missing wedge of over 100 degrees - a scenario where conventional methods fail. Notably, it also improves the reconstruction in case of sparse projections, despite the network not being specifically trained for that. This demonstrates the robustness and generality of our method of addressing commonly occurring challenges in 3D x-ray imaging applications for real-world problems.
Training Sparse Neural Network by Constraining Synaptic Weight on Unit Lp Sphere
Mar 30, 2021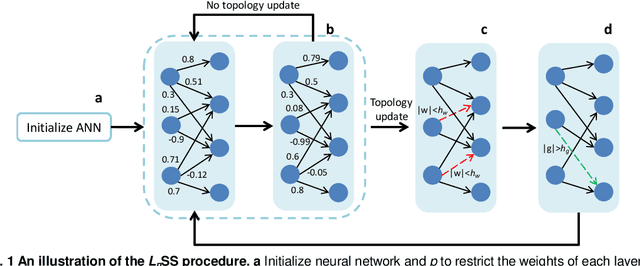
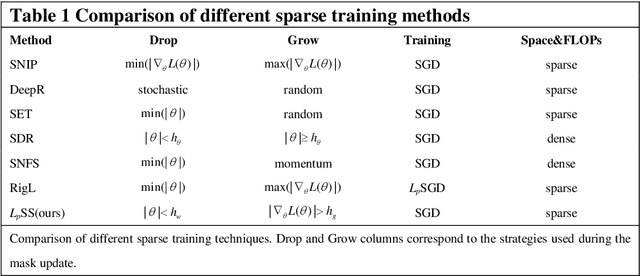
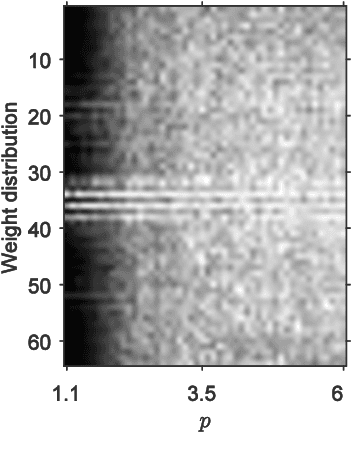

Sparse deep neural networks have shown their advantages over dense models with fewer parameters and higher computational efficiency. Here we demonstrate constraining the synaptic weights on unit Lp-sphere enables the flexibly control of the sparsity with p and improves the generalization ability of neural networks. Firstly, to optimize the synaptic weights constrained on unit Lp-sphere, the parameter optimization algorithm, Lp-spherical gradient descent (LpSGD) is derived from the augmented Empirical Risk Minimization condition, which is theoretically proved to be convergent. To understand the mechanism of how p affects Hoyer's sparsity, the expectation of Hoyer's sparsity under the hypothesis of gamma distribution is given and the predictions are verified at various p under different conditions. In addition, the "semi-pruning" and threshold adaptation are designed for topology evolution to effectively screen out important connections and lead the neural networks converge from the initial sparsity to the expected sparsity. Our approach is validated by experiments on benchmark datasets covering a wide range of domains. And the theoretical analysis pave the way to future works on training sparse neural networks with constrained optimization.