 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Sparse Neural Network by Constraining Synaptic Weight on Unit Lp Sphere
Paper and Code
Mar 30, 2021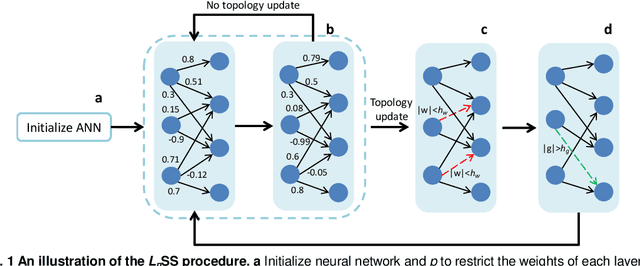
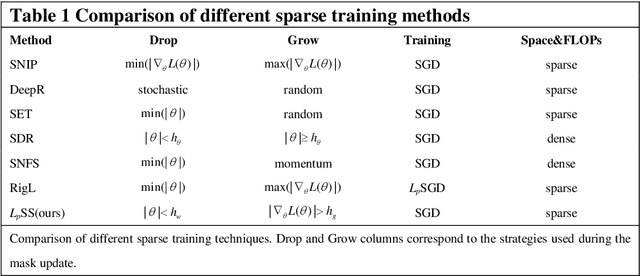
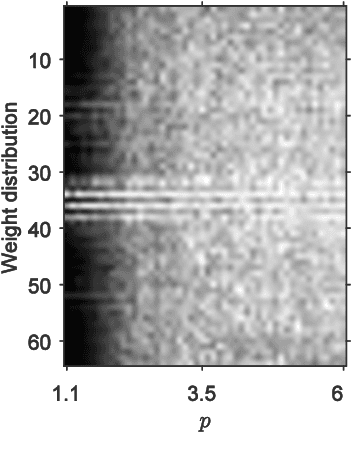

Sparse deep neural networks have shown their advantages over dense models with fewer parameters and higher computational efficiency. Here we demonstrate constraining the synaptic weights on unit Lp-sphere enables the flexibly control of the sparsity with p and improves the generalization ability of neural networks. Firstly, to optimize the synaptic weights constrained on unit Lp-sphere, the parameter optimization algorithm, Lp-spherical gradient descent (LpSGD) is derived from the augmented Empirical Risk Minimization condition, which is theoretically proved to be convergent. To understand the mechanism of how p affects Hoyer's sparsity, the expectation of Hoyer's sparsity under the hypothesis of gamma distribution is given and the predictions are verified at various p under different conditions. In addition, the "semi-pruning" and threshold adaptation are designed for topology evolution to effectively screen out important connections and lead the neural networks converge from the initial sparsity to the expected sparsity. Our approach is validated by experiments on benchmark datasets covering a wide range of domains. And the theoretical analysis pave the way to future works on training sparse neural networks with constrained optimization.