 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-critical Sequence Training for Automatic Speech Recognition
Apr 13, 2022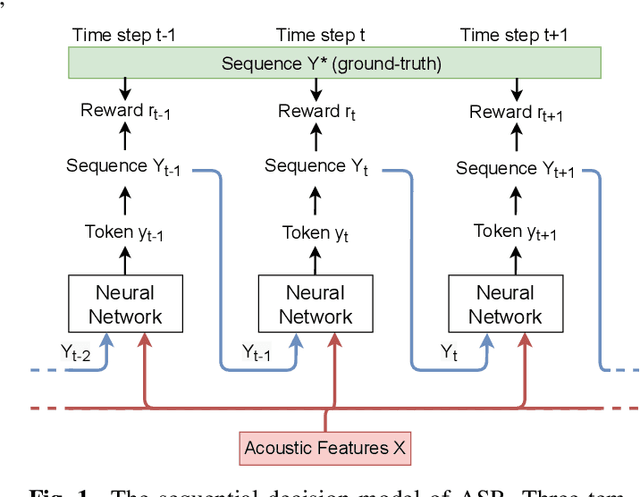
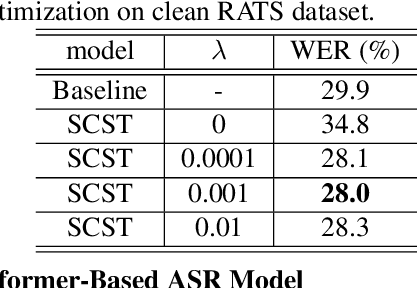
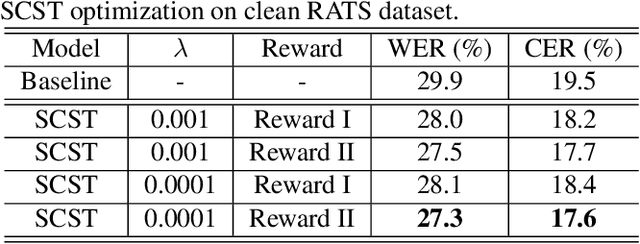
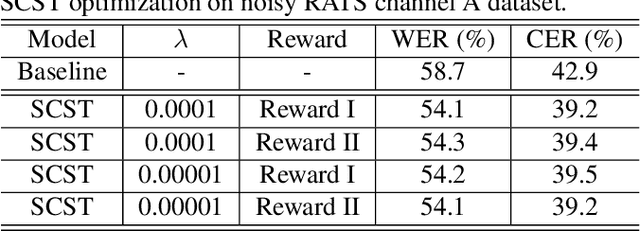
Although automatic speech recognition (ASR) task has gained remarkable success by sequence-to-sequence models, there are two main mismatches between its training and testing that might lead to performance degradation: 1) The typically used cross-entropy criterion aims to maximize log-likelihood of the training data, while the performance is evaluated by word error rate (WER), not log-likelihood; 2) The teacher-forcing method leads to the dependence on ground truth during training, which means that model has never been exposed to its own prediction before testing. In this paper, we propose an optimization method called self-critical sequence training (SCST) to make the training procedure much closer to the testing phase. As a reinforcement learning (RL) based method, SCST utilizes a customized reward function to associate the training criterion and WER. Furthermore, it removes the reliance on teacher-forcing and harmonizes the model with respect to its inference procedure. We conducted experiments on both clean and noisy speech datasets, and the results show that the proposed SCST respectively achieves 8.7% and 7.8% relative improvements over the baseline in terms of WER.
Interactive Audio-text Representation for Automated Audio Captioning with Contrastive Learning
Apr 12, 2022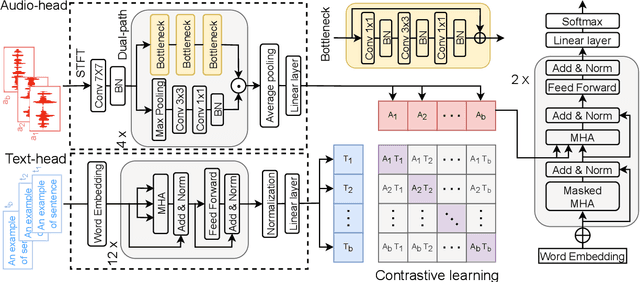

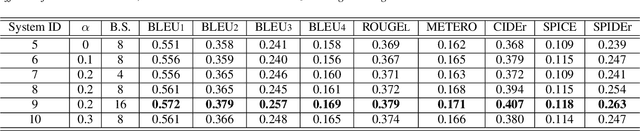
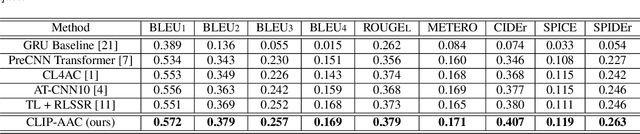
Automated Audio captioning (AAC) is a cross-modal task that generates natural language to describe the content of input audio. Most prior works usually extract single-modality acoustic features and are therefore sub-optimal for the cross-modal decoding task. In this work, we propose a novel AAC system called CLIP-AAC to learn interactive cross-modality representation with both acoustic and textual information. Specifically, the proposed CLIP-AAC introduces an audio-head and a text-head in the pre-trained encoder to extract audio-text information. Furthermore, we also apply contrastive learning to narrow the domain difference by learning the correspondence between the audio signal and its paired captions. Experimental results show that the proposed CLIP-AAC approach surpasses the best baseline by a significant margin on the Clotho dataset in terms of NLP evaluation metrics. The ablation study indicates that both the pre-trained model and contrastive learning contribute to the performance gain of the AAC model.