 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Discourse-level Multi-scale Prosodic Model for Fine-grained Emotion Analysis
Sep 21, 2023This paper explores predicting suitable prosodic features for fine-grained emotion analysis from the discourse-level text. To obtain fine-grained emotional prosodic features as predictive values for our model, we extract a phoneme-level Local Prosody Embedding sequence (LPEs) and a Global Style Embedding as prosodic speech features from the speech with the help of a style transfer model. We propose a Discourse-level Multi-scale text Prosodic Model (D-MPM) that exploits multi-scale text to predict these two prosodic features. The proposed model can be used to analyze better emotional prosodic features and thus guide the speech synthesis model to synthesize more expressive speech. To quantitatively evaluate the proposed model, we contribute a new and large-scale Discourse-level Chinese Audiobook (DCA) dataset with more than 13,000 utterances annotated sequences to evaluate the proposed model. Experimental results on the DCA dataset show that the multi-scale text information effectively helps to predict prosodic features, and the discourse-level text improves both the overall coherence and the user experience. More interestingly, although we aim at the synthesis effect of the style transfer model, the synthesized speech by the proposed text prosodic analysis model is even better than the style transfer from the original speech in some user evaluation indicators.
Towards Cross-speaker Reading Style Transfer on Audiobook Dataset
Aug 19, 2022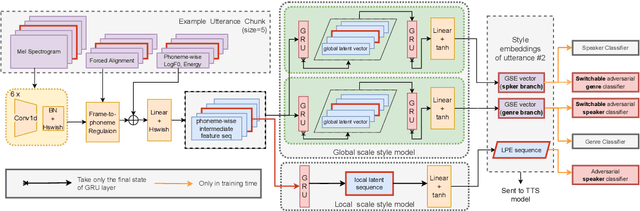
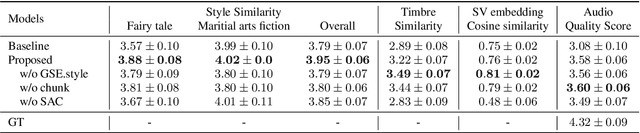

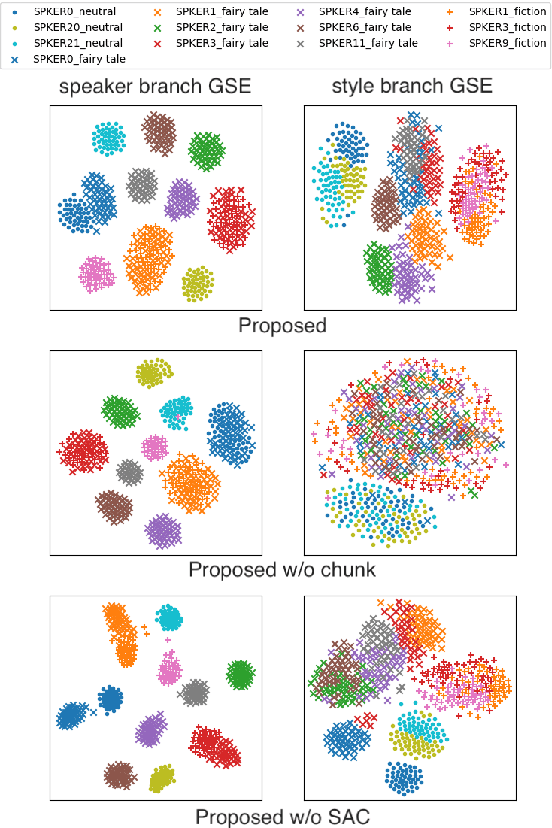
Cross-speaker style transfer aims to extract the speech style of the given reference speech, which can be reproduced in the timbre of arbitrary target speakers. Existing methods on this topic have explored utilizing utterance-level style labels to perform style transfer via either global or local scale style representations. However, audiobook datasets are typically characterized by both the local prosody and global genre, and are rarely accompanied by utterance-level style labels. Thus, properly transferring the reading style across different speakers remains a challenging task. This paper aims to introduce a chunk-wise multi-scale cross-speaker style model to capture both the global genre and the local prosody in audiobook speeches. Moreover, by disentangling speaker timbre and style with the proposed switchable adversarial classifiers, the extracted reading style is made adaptable to the timbre of different speakers. Experiment results confirm that the model manages to transfer a given reading style to new target speakers. With the support of local prosody and global genre type predictor, the potentiality of the proposed method in multi-speaker audiobook generation is further revealed.