 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedScale: Benchmarking Model and System Performance of Federated Learning
May 24, 2021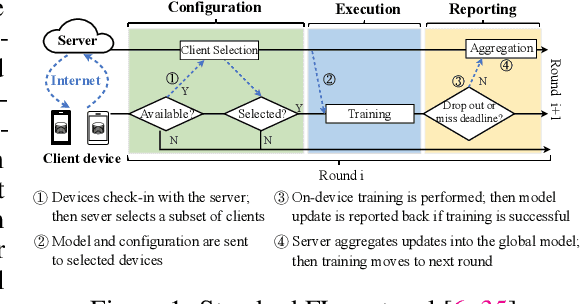
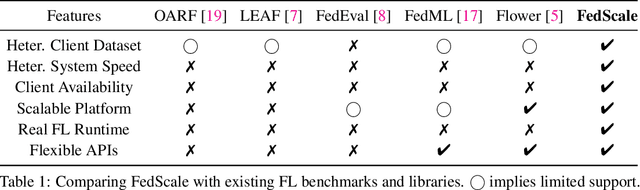
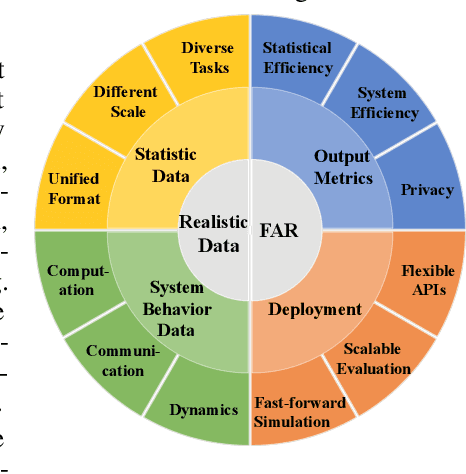
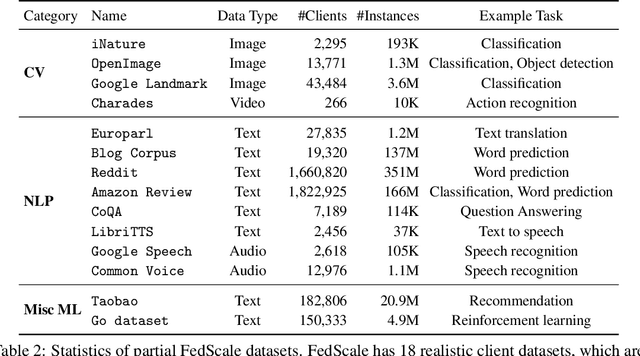
We present FedScale, a diverse set of challenging and realistic benchmark datasets to facilitate scalable, comprehensive, and reproducible federated learning (FL) research. FedScale datasets are large-scale, encompassing a diverse range of important FL tasks, such as image classification, object detection, language modeling, speech recognition, and reinforcement learning. For each dataset, we provide a unified evaluation protocol using realistic data splits and evaluation metrics. To meet the pressing need for reproducing realistic FL at scale, we have also built an efficient evaluation platform to simplify and standardize the process of FL experimental setup and model evaluation. Our evaluation platform provides flexible APIs to implement new FL algorithms and include new execution backends with minimal developer efforts. Finally, we perform indepth benchmark experiments on these datasets. Our experiments suggest that FedScale presents significant challenges of heterogeneity-aware co-optimizations of the system and statistical efficiency under realistic FL characteristics, indicating fruitful opportunities for future research. FedScale is open-source with permissive licenses and actively maintained, and we welcome feedback and contributions from the community.
Oort: Informed Participant Selection for Scalable Federated Learning
Oct 12, 2020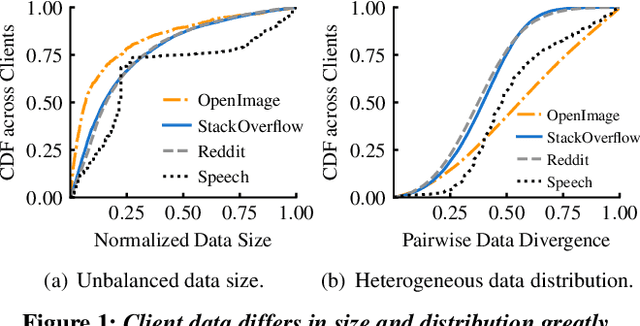
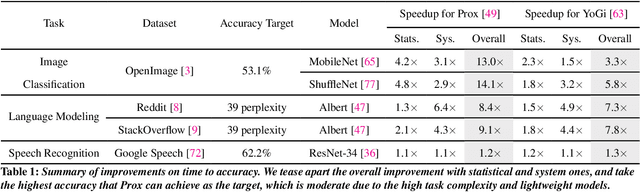
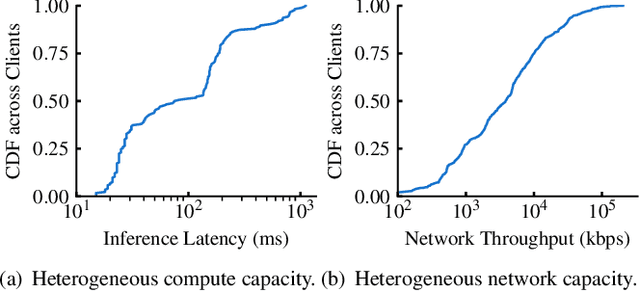
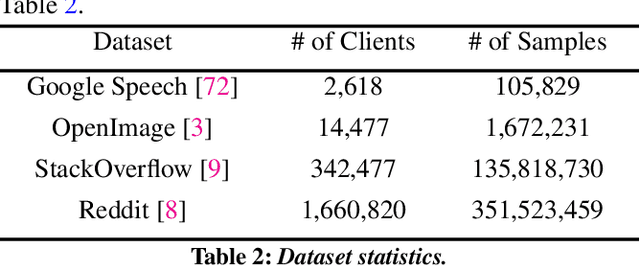
Federated Learning (FL) is an emerging direction in distributed machine learning (ML) that enables in-situ model training and testing on edge data. Despite having the same end goals as traditional ML, FL executions differ significantly in scale, spanning thousands to millions of participating devices. As a result, data characteristics and device capabilities vary widely across clients. Yet, existing efforts randomly select FL participants, which leads to poor model and system efficiency. In this paper, we propose Kuiper to improve the performance of federated training and testing with guided participant selection. With an aim to improve time-to-accuracy performance in model training, Kuiper prioritizes the use of those clients who have both data that offers the greatest utility in improving model accuracy and the capability to run training quickly. To enable FL developers to interpret their results in model testing, Kuiper enforces their requirements on the distribution of participant data while improving the duration of federated testing by cherry-picking clients. Our evaluation shows that, compared to existing participant selection mechanisms, Kuiper improves time-to-accuracy performance by 1.2x-14.1x and final model accuracy by 1.3%-9.8%, while efficiently enforcing developer requirements on data distributions at the scale of millions of clients.