 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMU-MIMO Symbol-Level Precoding for QAM Constellations with Maximum Likelihood Receivers
Oct 29, 2024In this paper, we investigate symbol-level precoding (SLP) and efficient decoding techniques for downlink transmission, where we focus on scenarios where the base station (BS) transmits multiple QAM constellation streams to users equipped with multiple receive antennas. We begin by formulating a joint symbol-level transmit precoding and receive combining optimization problem. This coupled problem is addressed by employing the alternating optimization (AO) method, and closed-form solutions are derived by analyzing the obtained two subproblems. Furthermore, to address the dependence of the receive combining matrix on the transmit signals, we switch to maximum likelihood detection (MLD) method for decoding. Notably, we have demonstrated that the smallest singular value of the precoding matrix significantly impacts the performance of MLD method. Specifically, a lower value of the smallest singular value results in degraded detection performance. Additionally, we show that the traditional SLP matrix is rank-one, making it infeasible to directly apply MLD at the receiver end. To circumvent this limitation, we propose a novel symbol-level smallest singular value maximization problem, termed SSVMP, to enable SLP in systems where users employ the MLD decoding approach. Moreover, to reduce the number of variables to be optimized, we further derive a more generic semidefinite programming (SDP)-based optimization problem. Numerical results validate the effectiveness of our proposed schemes and demonstrate that they significantly outperform the traditional block diagonalization (BD)-based method.
Brain-like Functional Organization within Large Language Models
Oct 25, 2024


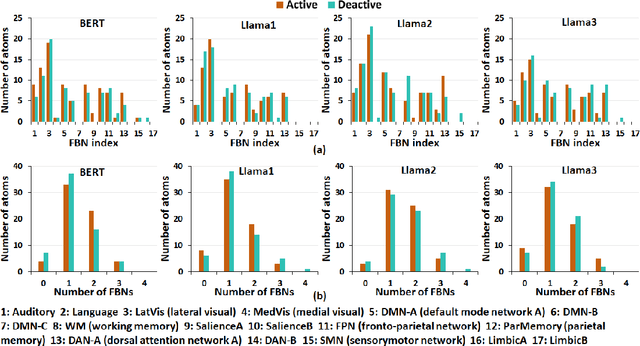
The human brain has long inspired the pursuit of artificial intelligence (AI). Recently, neuroimaging studies provide compelling evidence of alignment between the computational representation of artificial neural networks (ANNs) and the neural responses of the human brain to stimuli, suggesting that ANNs may employ brain-like information processing strategies. While such alignment has been observed across sensory modalities--visual, auditory, and linguistic--much of the focus has been on the behaviors of artificial neurons (ANs) at the population level, leaving the functional organization of individual ANs that facilitates such brain-like processes largely unexplored. In this study, we bridge this gap by directly coupling sub-groups of artificial neurons with functional brain networks (FBNs), the foundational organizational structure of the human brain. Specifically, we extract representative patterns from temporal responses of ANs in large language models (LLMs), and use them as fixed regressors to construct voxel-wise encoding models to predict brain activity recorded by functional magnetic resonance imaging (fMRI). This framework links the AN sub-groups to FBNs, enabling the delineation of brain-like functional organization within LLMs. Our findings reveal that LLMs (BERT and Llama 1-3) exhibit brain-like functional architecture, with sub-groups of artificial neurons mirroring the organizational patterns of well-established FBNs. Notably, the brain-like functional organization of LLMs evolves with the increased sophistication and capability, achieving an improved balance between the diversity of computational behaviors and the consistency of functional specializations. This research represents the first exploration of brain-like functional organization within LLMs, offering novel insights to inform the development of artificial general intelligence (AGI) with human brain principles.
Local Contrastive Learning for Medical Image Recognition
Mar 24, 2023



The proliferation of Deep Learning (DL)-based methods for radiographic image analysis has created a great demand for expert-labeled radiology data. Recent self-supervised frameworks have alleviated the need for expert labeling by obtaining supervision from associated radiology reports. These frameworks, however, struggle to distinguish the subtle differences between different pathologies in medical images. Additionally, many of them do not provide interpretation between image regions and text, making it difficult for radiologists to assess model predictions. In this work, we propose Local Region Contrastive Learning (LRCLR), a flexible fine-tuning framework that adds layers for significant image region selection as well as cross-modality interaction. Our results on an external validation set of chest x-rays suggest that LRCLR identifies significant local image regions and provides meaningful interpretation against radiology text while improving zero-shot performance on several chest x-ray medical findings.