 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-assisted Optimization of the ECCE Tracking System at the Electron Ion Collider
May 20, 2022The Electron-Ion Collider (EIC) is a cutting-edge accelerator facility that will study the nature of the "glue" that binds the building blocks of the visible matter in the universe. The proposed experiment will be realized at Brookhaven National Laboratory in approximately 10 years from now, with detector design and R&D currently ongoing. Notably, EIC is one of the first large-scale facilities to leverage Artificial Intelligence (AI) already starting from the design and R&D phases. The EIC Comprehensive Chromodynamics Experiment (ECCE) is a consortium that proposed a detector design based on a 1.5T solenoid. The EIC detector proposal review concluded that the ECCE design will serve as the reference design for an EIC detector. Herein we describe a comprehensive optimization of the ECCE tracker using AI. The work required a complex parametrization of the simulated detector system. Our approach dealt with an optimization problem in a multidimensional design space driven by multiple objectives that encode the detector performance, while satisfying several mechanical constraints. We describe our strategy and show results obtained for the ECCE tracking system. The AI-assisted design is agnostic to the simulation framework and can be extended to other sub-detectors or to a system of sub-detectors to further optimize the performance of the EIC detector.
AI-optimized detector design for the future Electron-Ion Collider: the dual-radiator RICH case
Nov 13, 2019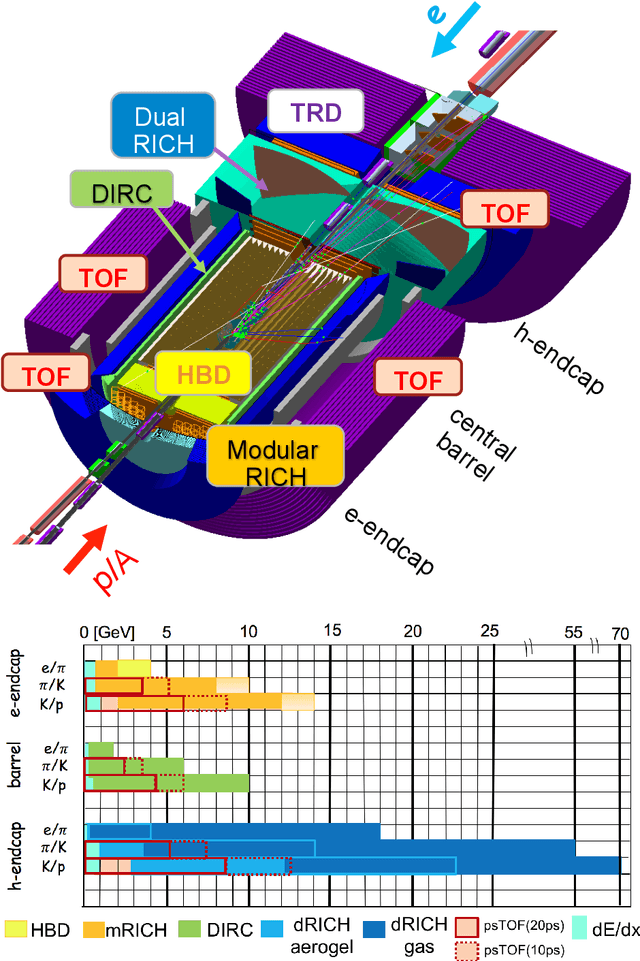
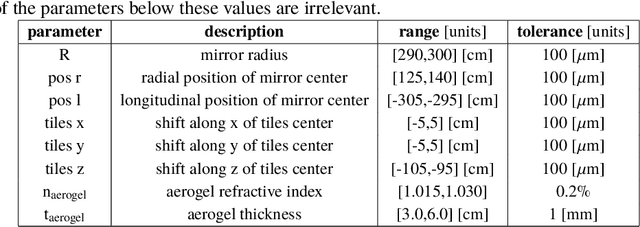
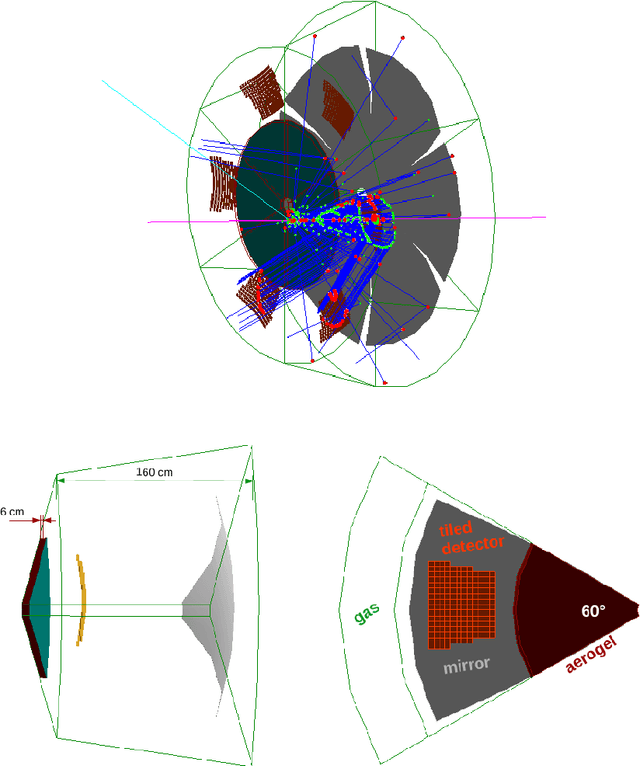

Advanced detector R&D requires performing computationally intensive and detailed simulations as part of the detector-design optimization process. We propose a general approach to this process based on Bayesian optimization and machine learning that encodes detector requirements. As a case study, we focus on the design of the dual-radiator Ring Imaging Cherenkov (dRICH) detector under development as part of the particle-identification system at the future Electron-Ion Collider (EIC). The EIC is a US-led frontier accelerator project for nuclear physics, which has been proposed to further explore the structure and interactions of nuclear matter at the scale of sea quarks and gluons. We show that the detector design obtained with our automated and highly parallelized framework outperforms the baseline dRICH design. Our approach can be applied to any detector R&D, provided that realistic simulations are available.
Compressed Sensing with Probability-based Prior Information
Oct 27, 2019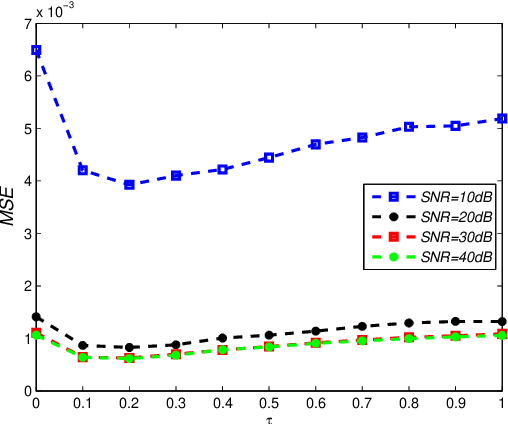
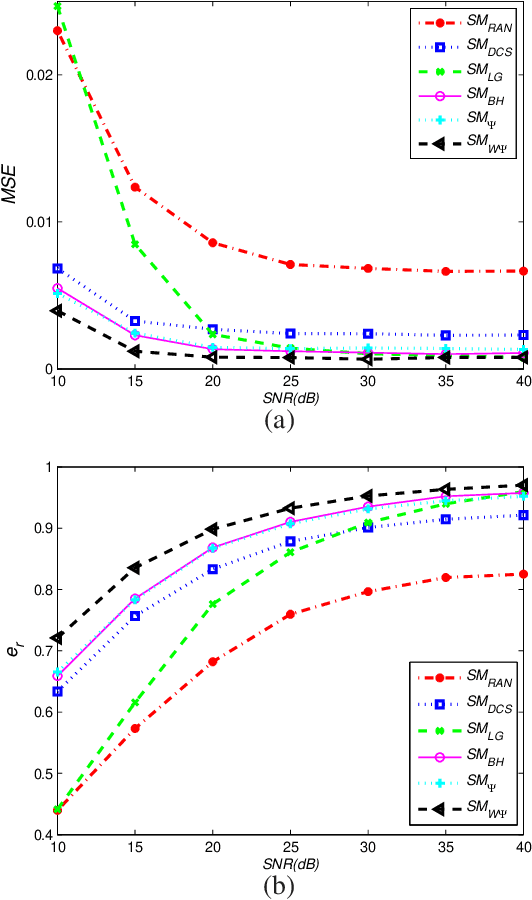
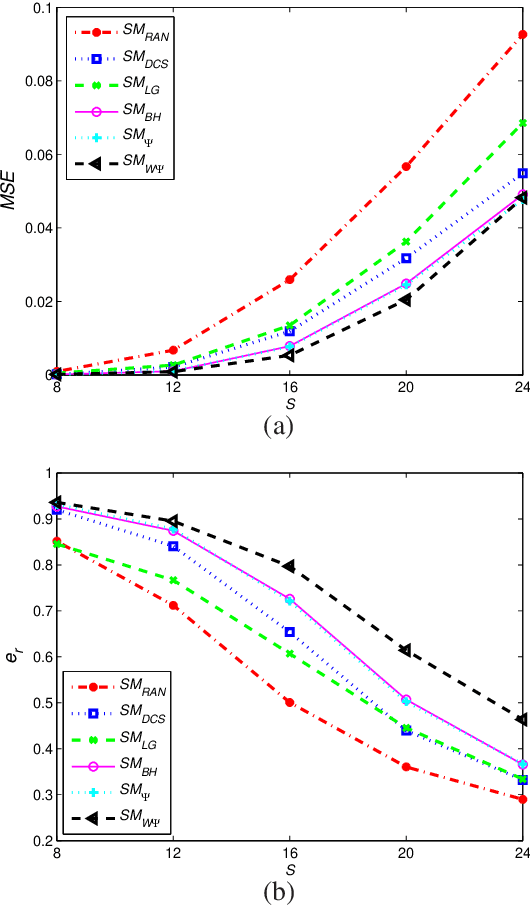
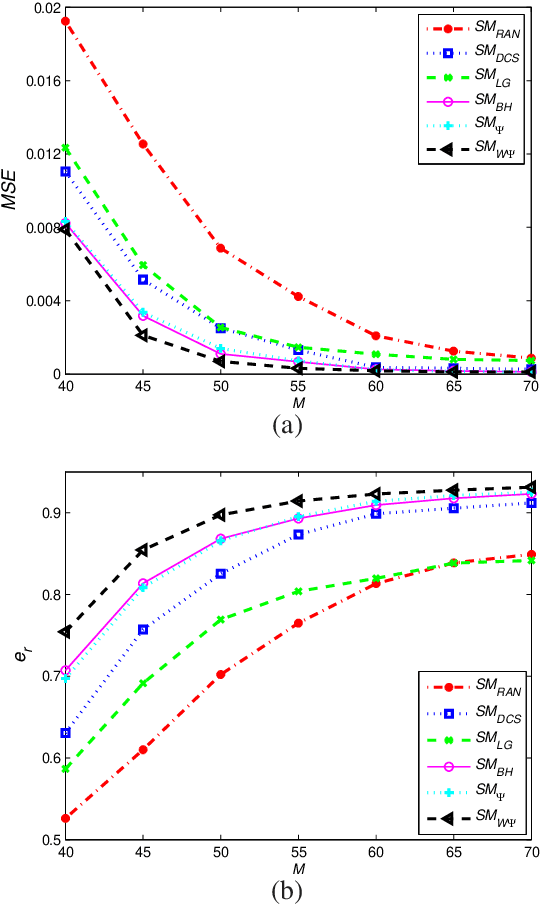
This paper deals with the design of a sensing matrix along with a sparse recovery algorithm by utilizing the probability-based prior information for compressed sensing system. With the knowledge of the probability for each atom of the dictionary being used, a diagonal weighted matrix is obtained and then the sensing matrix is designed by minimizing a weighted function such that the Gram of the equivalent dictionary is as close to the Gram of dictionary as possible. An analytical solution for the corresponding sensing matrix is derived which leads to low computational complexity. We also exploit this prior information through the sparse recovery stage and propose a probability-driven orthogonal matching pursuit algorithm that improves the accuracy of the recovery. Simulations for synthetic data and application scenarios of surveillance video are carried out to compare the performance of the proposed methods with some existing algorithms. The results reveal that the proposed CS system outperforms existing CS systems.
Bipartite graph partitioning and data clustering
Aug 27, 2001



Many data types arising from data mining applications can be modeled as bipartite graphs, examples include terms and documents in a text corpus, customers and purchasing items in market basket analysis and reviewers and movies in a movie recommender system. In this paper, we propose a new data clustering method based on partitioning the underlying bipartite graph. The partition is constructed by minimizing a normalized sum of edge weights between unmatched pairs of vertices of the bipartite graph. We show that an approximate solution to the minimization problem can be obtained by computing a partial singular value decomposition (SVD) of the associated edge weight matrix of the bipartite graph. We point out the connection of our clustering algorithm to correspondence analysis used in multivariate analysis. We also briefly discuss the issue of assigning data objects to multiple clusters. In the experimental results, we apply our clustering algorithm to the problem of document clustering to illustrate its effectiveness and efficiency.